Integrating Data
in Comparative Linguistics

Agenda
- Background
- Data Integration
- Cross-Linguistic Data Formats
- Case Studies
- Outlook
Background

Background
Constructs
Major constructs in linguistics are quite easy to identify:
- language
- sentence
- word
- meaning (concept)
- sounds
- grammatical rules
- phonotactic rules
Background
Constructs
What is a language?
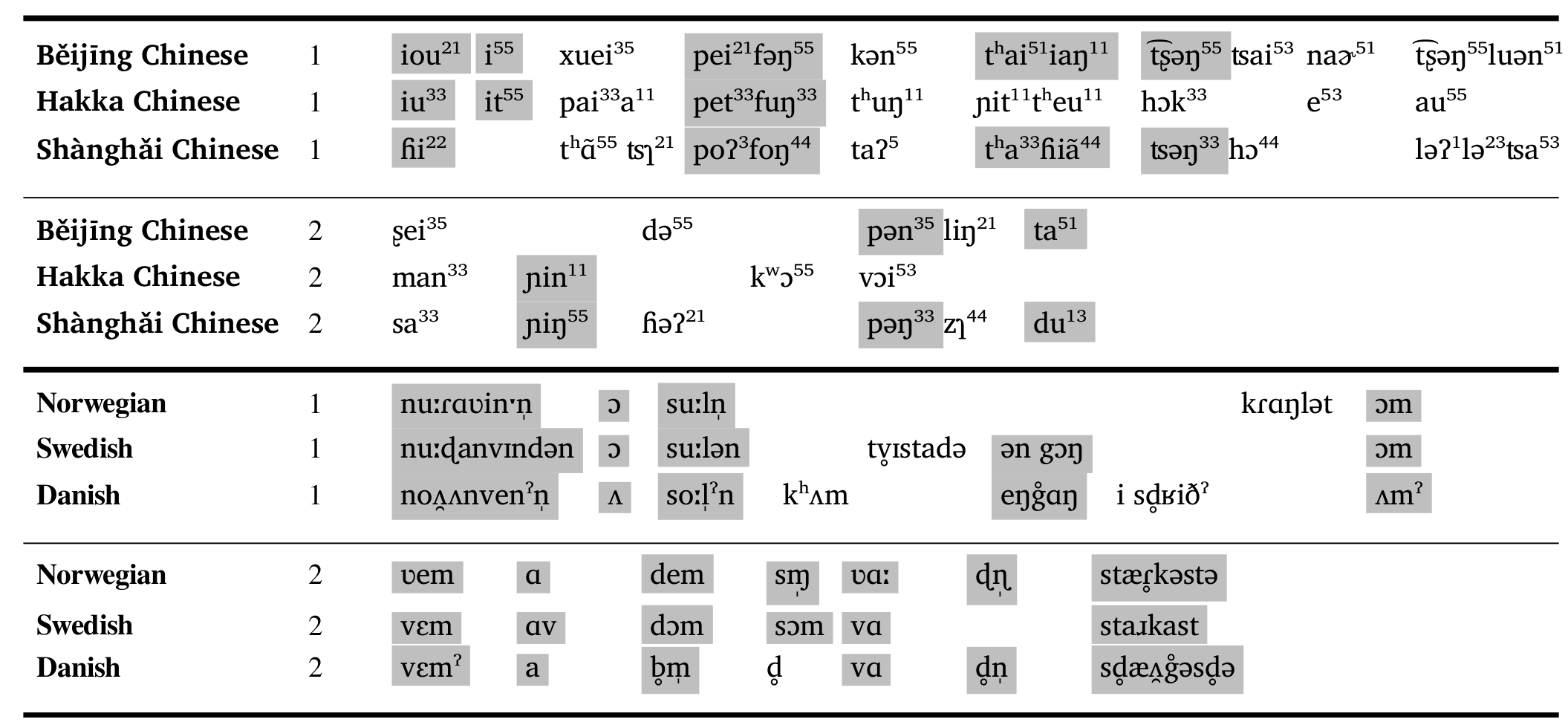
Background
Constructs
What is a language?
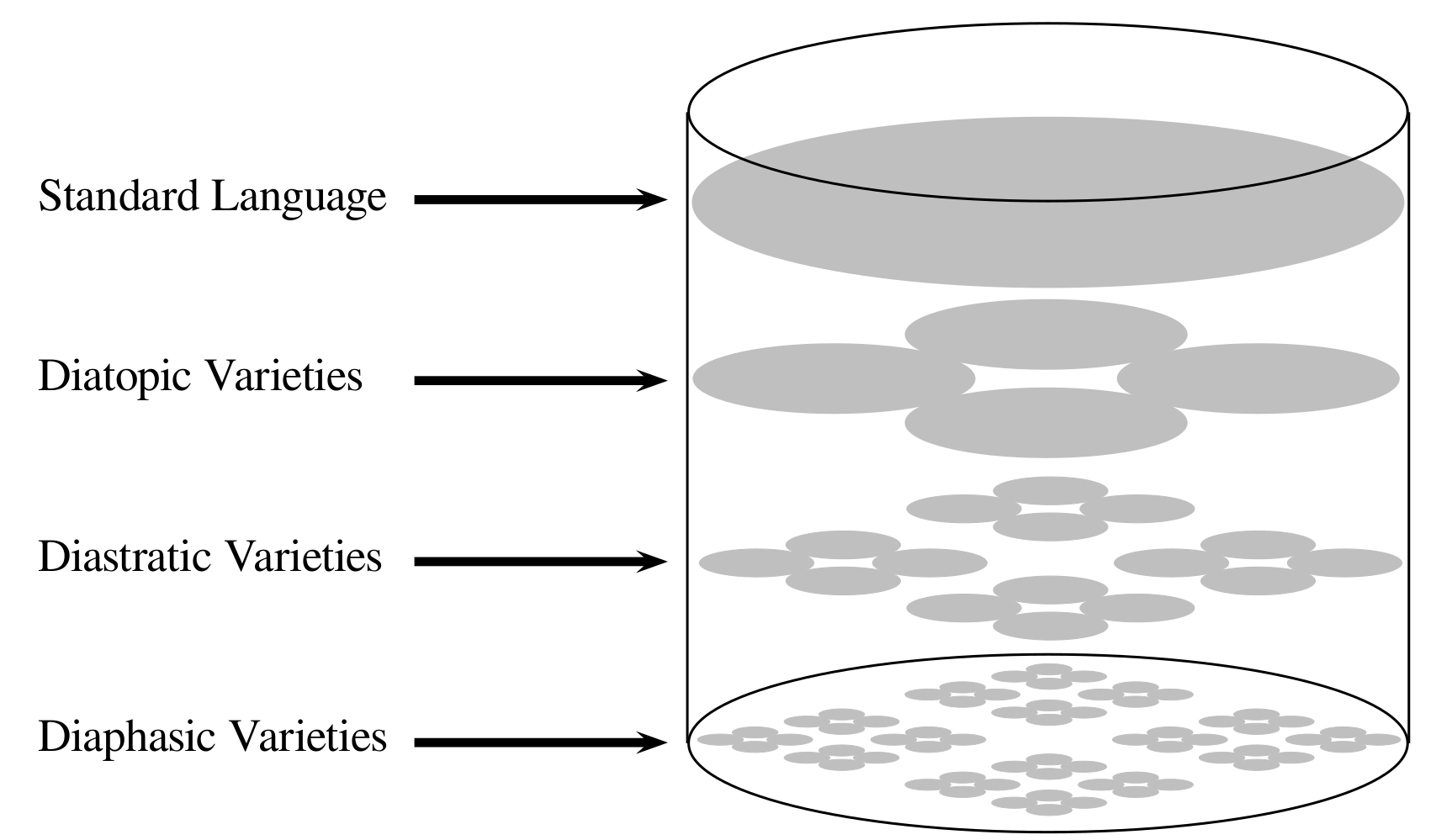
Background
Constructs
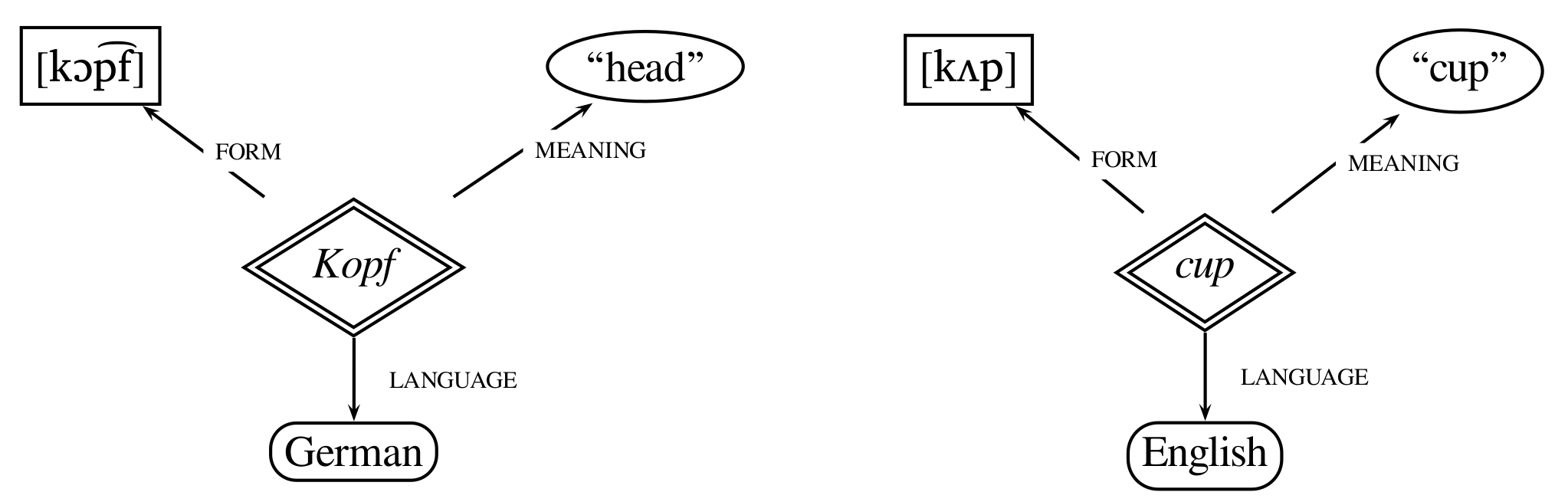
What is a Linguistic Sign?
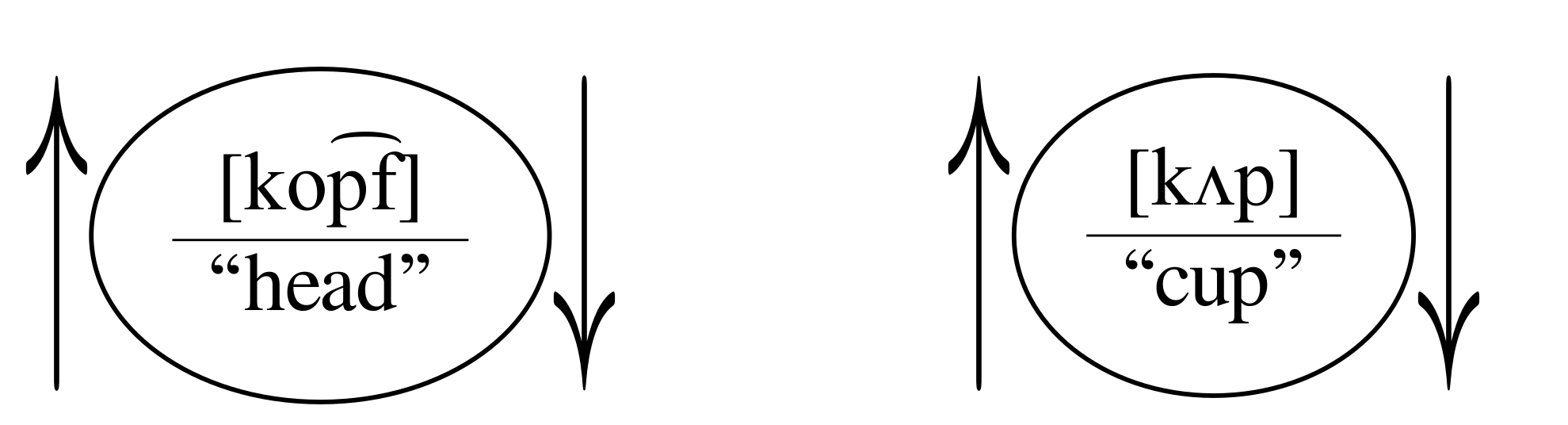
Background
Constructs
What is a Linguistic Sign?
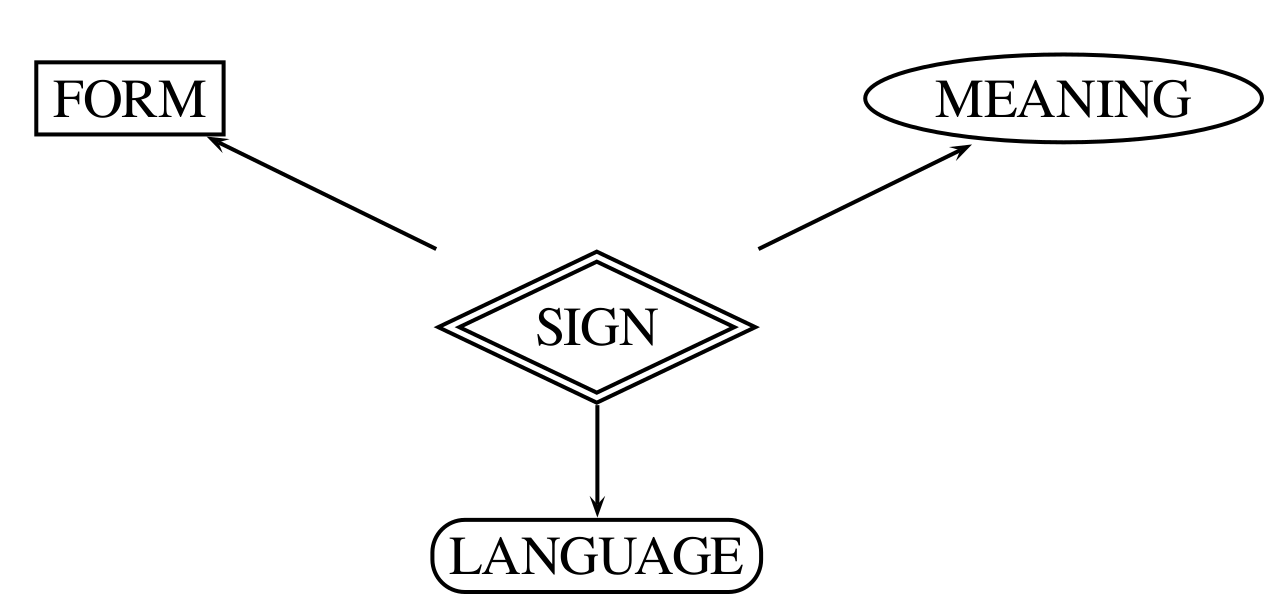
Background
Constructs
What is a Linguistic Sign?
Background
Constructs
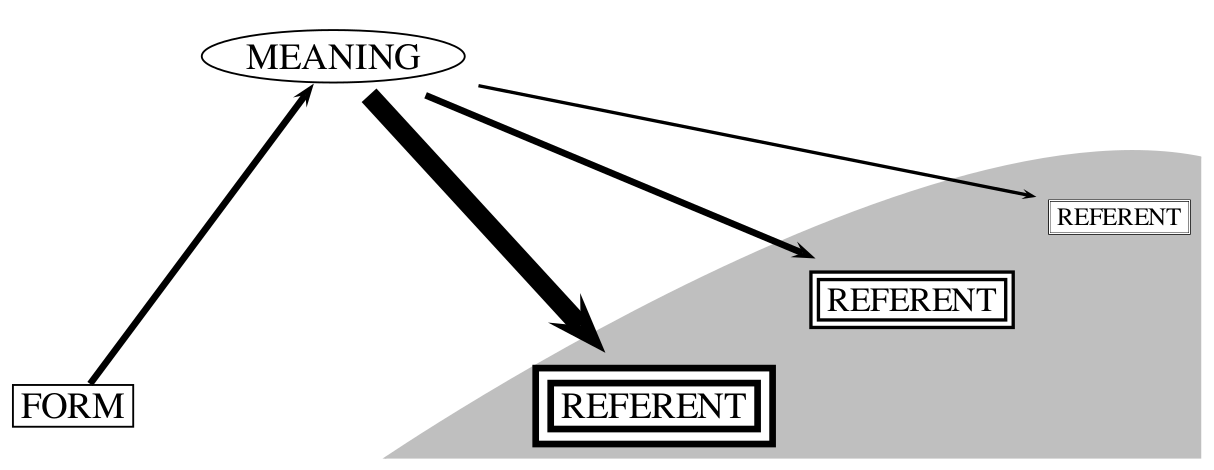
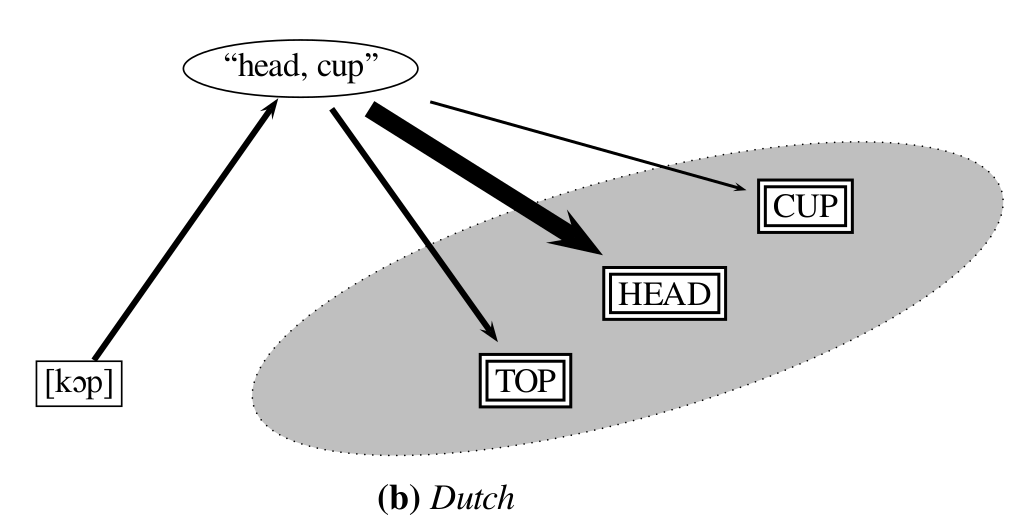
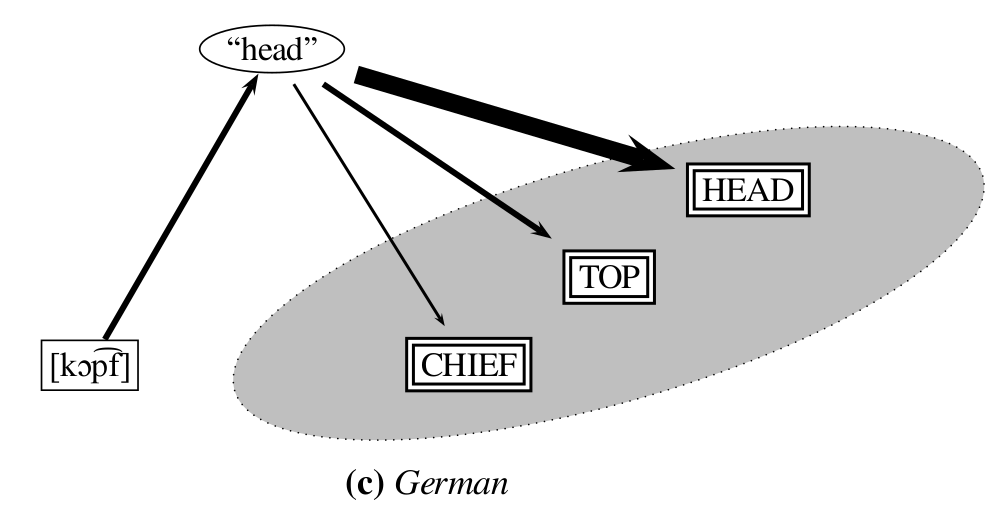
What is a Concept?
Background
Constructs
What is a Concept?
Background
Constructs
What is a Concept?
Background
Constructs
What is a Sound?

Background
Constructs
What is a Sound?
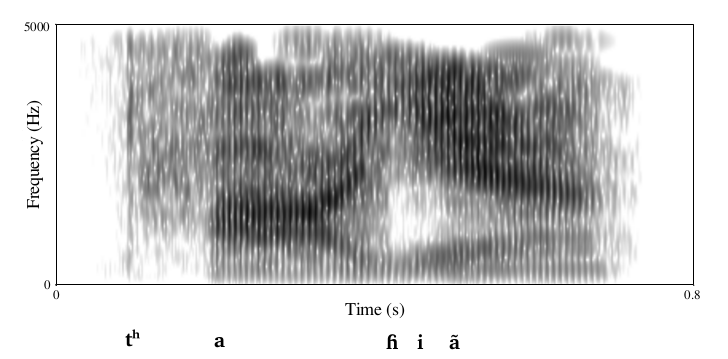
Background
Constructs
Summary: Linguists have problems to define:
- what a language is and where to draw its boundaries,
- discrete concepts,
- discrete sounds,
although they live fairly well by not reminding themselves of this too often.
Often, linguists emphasize that every language is unique, showing structures that are ultimately incomparable with the structures observed in other languages.
Background
Language Comparison
Windows to our past
 |
Comparative linguistics has provided us with many new insights into the past of our languages. |
Background
Language Comparison
Windows to cognition
 |
Comparative linguistics has a great and so far underexplored potential to help us learn more about human cognition. |
Background
Language Comparison
Windows to culture
 |
Comparative linguistics can help us to distinguish culturally specific traits from universal tendencies. |
Background
Language Comparison
But comparing languages has limits We face many problems, resulting largely from the lack of
- Standards
- Agreed-Upon Methods
- Comparable Data
Background
Language Comparison
Lack of Standards
 |
Linguists rarely follow standards in naming languages, referencing concepts, or transcribing words. |
Background
Language Comparison
Lack of Agreed-Upon Methods
 |
Linguists use a large amount of different methods and barely agree even on the basic procedures for inference, as specifically witnessed by the "comparative method", which differs from scholar to scholar and has never been properly formalized. |
Background
Language Comparison
Lack of Comparable Data
 |
Linguistic data for different or identical languages are largely incomparable, since key aspects of the data have often not been unified, as reflected in idiosyncratic elicitation glosses, language names, or transcription systems. |
Background
Computer-Assisted Language Comparison

The Quantitative Turn in Historical Linguistics
Background
Computer-Assisted Language Comparison

Expertendämmerung
Background
Computer-Assisted Language Comparison

Background
Computer-Assisted Language Comparison

Computer-Assisted Language Comparison (List 2016)
Background
Computer-Assisted Language Comparison

Computer-Assisted Language Comparison (List 2016)
Background
Computer-Assisted Language Comparison
Core ideas of the CALC framework
- Data must be human- and machine-readable
- Software is used to preprocess linguistic data and should specifically target linguistic problems rather than build on naive off-the-shelf solutions in machine learning
- Interfaces help linguists to access the data and to post-process and correct machine output
Data Integration

Data Integration
Background
Problems of Data in Comparative Linguistics
- non-formal prose descriptions
- language-internal description
- theoretically biased descriptions
Data Integration
Background
Non-Formal Description
Scholars often use prose in order to describe a language. Even if formal descriptions are discussed, these are never really tested, although this can be easily done nowadays with the help of computers.
Data Integration
Background
Language-Internal Description Assuming that languages are unique, scholars often describe languages in ways which are not comparable with other languages.
Data Integration
Background
Theoretically Biased Descriptions
Descriptions often follow a specific framework, or scholars claim they follow the framework, but the numerous frameworks in linguistics are largely incomparable, and rarely standardized, so that even a comparison of descriptions within the same framework may often be impossible.
Data Integration?
What is Data Integration?
What is Data Integration?
- Data integration means to assemble data from multiple sources in such a way that we can use aggregated information for various studies.
Data Integration?
What is Data Integration?
Current State in Comparative Linguistics
- Data are often not integrated, as we can see when looking at phoneme inventory datasets, which are not integrated with lexical sources, which are not integrated with grammatical sources, although scholars usually obtain the information from the same resources.
Data Integration?
What is Data Integration?
Data Integration vs. Data Collection
- Data integration is different from pure data collection, where pieces of data are usually selected from individual literature on particular languages, in a framework of data integration, we try to prepare resources in such a way that we can aggregate them directly, ideally in their completeness.
Workflows for Data Integration

Workflows for Data Integration
Major Stages
- [A] Digitization
- [B] Standardization
- [C] Annotation
Workflows for Data Integration
Major Stages: Digitization
Digitization requires often very specific approaches, due to
- the structure of the individual sources and
- the techniques that can be applied (OCR, hand-typing, etc.).
Workflows for Data Integration
Major Stages: Digitization
In order to control the consistency of the process, we make use of test-driven data curation (term coined by Robert Forkel) in a computer-assisted framework, that means, we
- versionize the work,
- test the basic characteristics of the data automatically with the help of unittests,
- write small, targeted web-based applications that enhance the digitization process.
Workflows for Data Integration
Major Stages: Standardization
(Retro)-standardization (or data lifting) is one of the core aspects of our recent efforts, expressed as part of the Cross-Linguistic Data Formats initiative (https://cldf.clld.org). This means we
- establish and curate reference catalogs (large collections of small-scale constructs for linguistic research objects, including languages, concepts, and sounds),
- parse digitized data semi-automatically in order to link data points to our reference catalogs,
- use test-driven data curation to guarantee the workflow passes our tests.
Workflows for Data Integration
Major Stages: Standardization
Reference Catalogs
- Glottolog (https://glottolog.org): reference catalogue for language varieties (languages and dialects), providing language identifiers, geolocations, classifications, and references.
- Concepticon (https://concepticon.clld.org): reference catalog for concepts, which are defined independently of concrete languages, providing concept identifiers, concept metadata, concept relations, and references.
- Cross-Linguistic Transcription Systems (https://clts.clld.org): reference catalogue for speech sounds (across different transcription systems and datasets), offering sound identifiers, feature-based sound descriptions, and references.
Workflows for Data Integration
Major Stages: Annotation
Annotation helps us to add information to a dataset which was not inherently given by the structure of the data before. For these tasks, we use
- targeted algorithms to pre-process the data, along with
- light-weight, interative annotation tools that help us to manually correct automatically preprocessed data.
Prime examples for annotation are: morpheme segmentation (assignment of morpheme boundaries), cognate annotation (assignment of etymological relationships).
Workflows for Data Integration
Flexible Workflows
Depending on the task, we set up clear-cut workflows and best-practice examples to train our colleagues in how to apply them.
When colleagues approach us, asking for help with their data, we often also develop specific workflows for their approach.
In all cases, we try to make sure that the data are
- versionized,
- tested, and
- archived.
Worfklows for Data Integration
Cross-Linguistic Data Formats: Idea
- linguists publish increasing amounts of digital data
- most data published are not comparable, as they are rarely standardized
- → standardizing data that has been published and encouraging scholars to standardize data along with its publication would help to increase the amount of comparable data out there
Worfklows for Data Integration
Cross-Linguistic Data Formats: History
- CLDF initiative goes back to 2014 (founded at the DLCE/MPI-SHH Jena)
- idea to use tabular data throughout
- employ the CSVW model by the W3C
- use Python packages for validation
- allow easy parsing / querying with Python, R, and SQL
Worfklows for Data Integration
Cross-Linguistic Data Formats: Propagation
- website and first version published in 2018 (https://cldf.clld.org) along with a paper (see details on the website)
- provide concrete examples how to present data in this form (e.g., by publishing blog posts at https://calc.hypotheses.org, or by mentioning CLDF in papers and providing data in CLDF, e.g., Sagart et al. 2019, PNAS, with lexical data at https://github.com/lexibank/sagartst)
- two main organizations: github.com/lexibank and github.com/cldf-datasets, one for lexical data, one for structural data
Worfklows for Data Integration
Cross-Linguistic Data Formats: Implementation
- tabular data in CSV form with metadata in JSON and sources in BibTeX, following the recommendations of the W3C for CSVW (tabular data on the web, 2013)
- pycldf package to query the data and to validate and to convert to sqlite
- integration of reference catalogs (Glottolog for languages, Concepticon for concepts, and CLTS for speech sounds, maybe Grammaticon for IGT in the future)
Workflows for Data Integration
CLDFBench: Idea
- provide a Python package that does the lifting of data
- retro-standardization and conversion of data from other formats can be done with Python code that is testable, modularizable, and transparent
- teach more and more people to work with CLDF
Workflows for Data Integration
CLDFBench: Application
- CLDFBench now underlies some 70 lexical and about 30 (?) structural datasets
- new CLDF datasets are all curated by means of CLDFbench instead of "pure" pycldf as before
- examples of how to use the library are published in various forms (e.g., also as blog posts at https://calc.hypotheses.org)
Workflows for Data Integration
CLDFBench: Example
- query WALS data with CLDF and CLDFBench
- blog post published today at https://calc.hypotheses.org
- explains how WALS data can be turned into tabular form of one single table to be used in other applications
Workflows for Data Integration
CLDFBench: Lexibank
- Lexibank (https://github.com/lexibank/lexibank-analysed) goes one step further by serving as a plugin for CLDFBench that offers specific operations for the standardization of wordlists
- The core of the Lexibank framework for standardizing wordlists is a repository, similar to Genbank, in which we have assembled more than 100 standardized datasets for more than 2000 different languages.
Examples
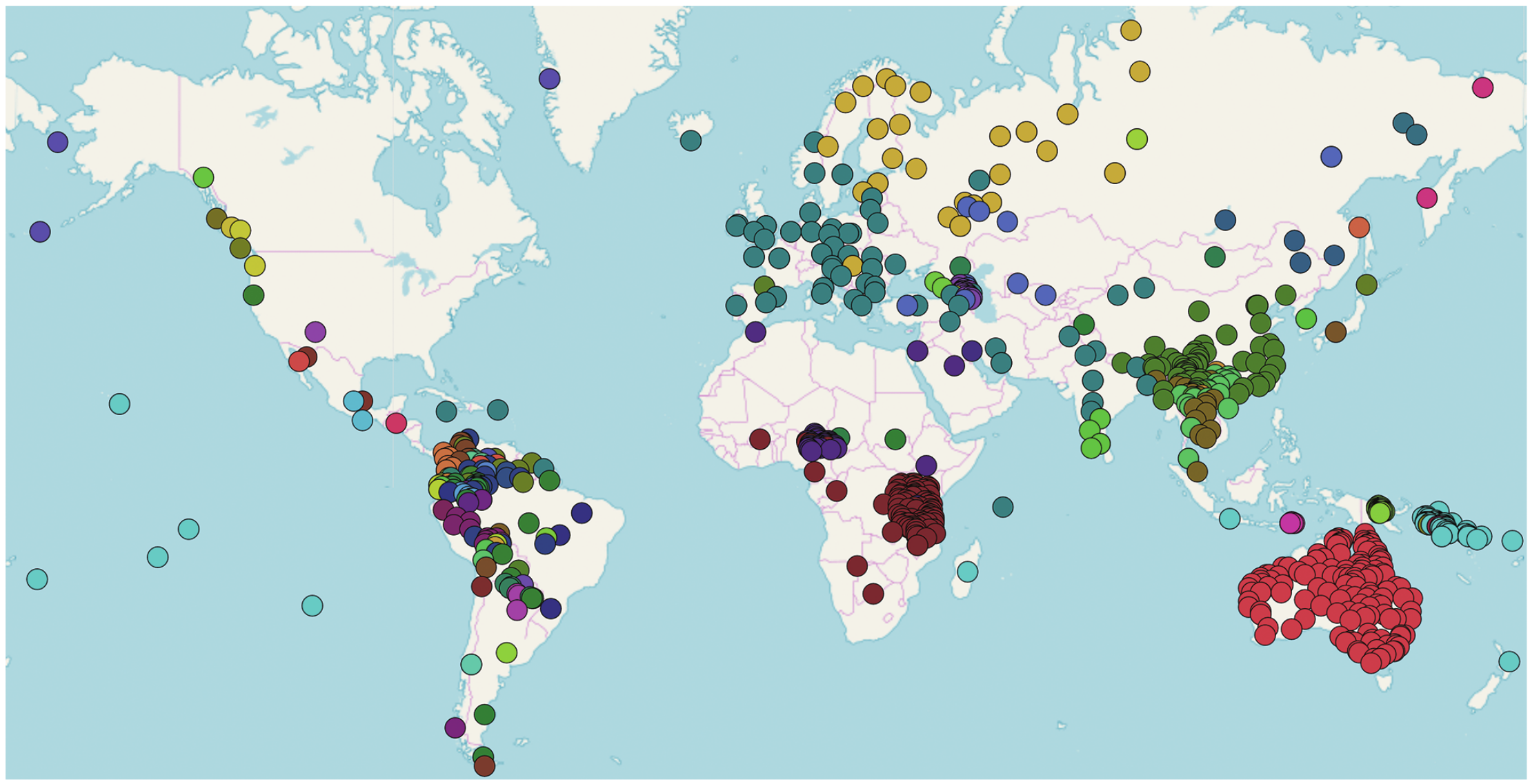
Examples
TPPSR
Examples
TPPSR
- The TPPSR (Tableaux Phonétiques des Patois Suisses Romands) presents data recorded between 1904 and 1907 in 62 villages to document a puzzling variety of French and Franco-Provençal dialects that is unparalleled in the Romance-speaking world.
- Louis Gauchat and his collaborators Jules Jeanjaquet and Ernest Tappolet collected data for a questionnaire consisting of short sentences that deal with everyday rural life. The questionnaire focuses on phonetics but covers also characteristic morphological and lexical features of local dialects.
Examples
TPPSR
- Gauchat and colleagues never succeded to map their data into geographic space, although they tried hard, after having published their material in tabular form.
- They created specific notations and had to create specific typesets in order to be able to print the complex characters.
Examples
TPPSR
- Our digital version of the TPPSR, available at https://tppsr.clld.org, makes use of our most advanced data lifting techniques.
- We link languages to geographic coordinates, we map concepts to the Concepticon reference catalog, and we also standardized the phonetic transcriptions with the help of Orthography Profiles (Moran and Cysouw 2019).
- By restoring the original sentences that the authors broke into tables, we managed to integrate the data in various ways.
Examples
Colexification Networks

Examples
Colexification Networks

Examples
Colexification Networks

Examples
Colexification Networks
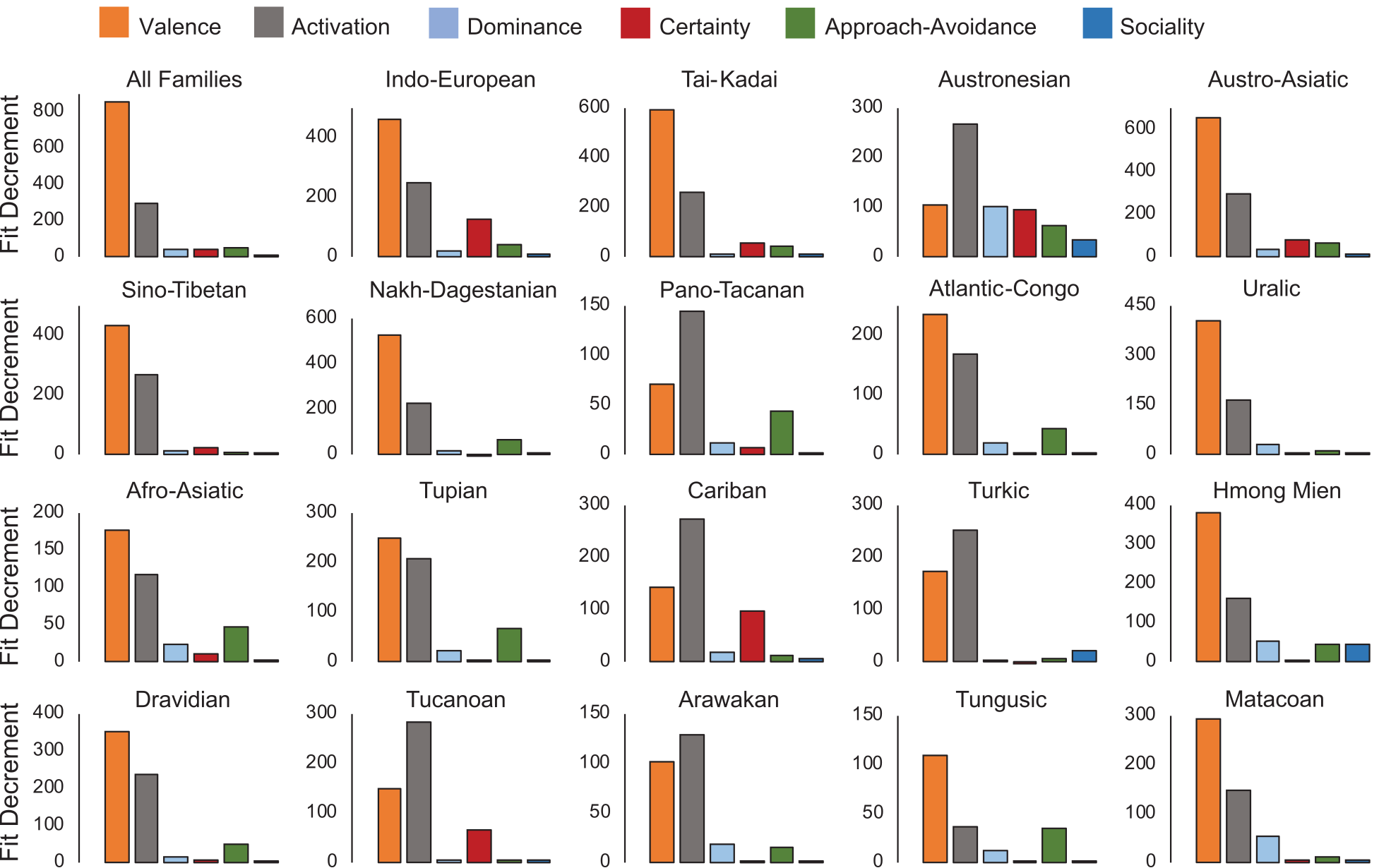
Database of Cross-Linguistic Colexifications (CLICS)
- assemble lexical datasets coded in CLDF to extract colexification patterns automatically
- use this to replace the not-so-easy-maintainable CLICS-1.0 database (List et al. 2014)
- restrict the curation of the data to the selection of a couple of base datasets (currently 30, Rzymski et al. 2020, see CLICS homepage at https://clics.clld.org)
- add minimal Python code to infer colexifications from the data
- represen the data as a CLLD app
Examples
Colexification Networks

Examples
Colexification Networks
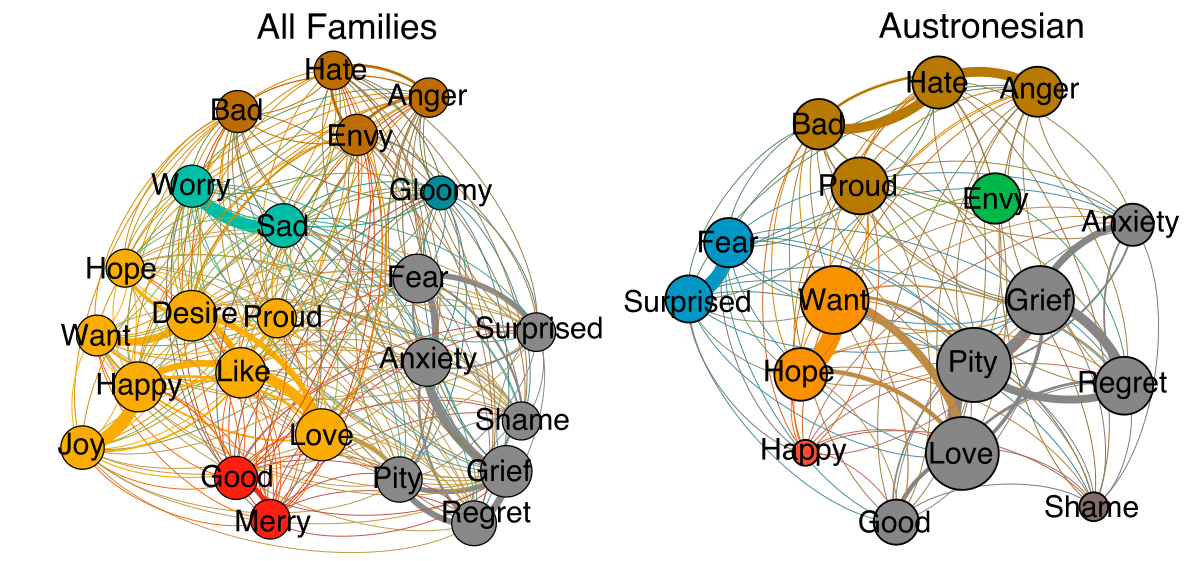
Examples
Colexification Networks

Examples
Colexification Networks
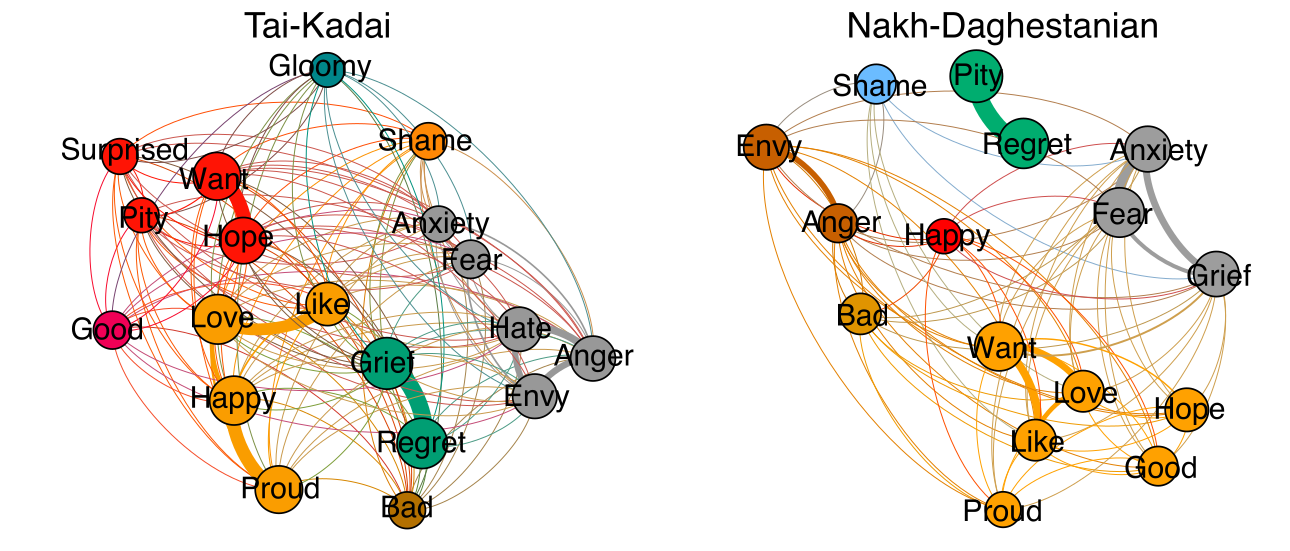
Examples
Colexification Networks
Examples
Norms, Ratings, and Relations
Background
Psychologists, social scientists, and linguists have assembled a huge amount of data on word and concept properties, that is, norms, ratings, and relations. Unfortunately, these data are rarely integrated.
Examples
Norms, Ratings, and Relations
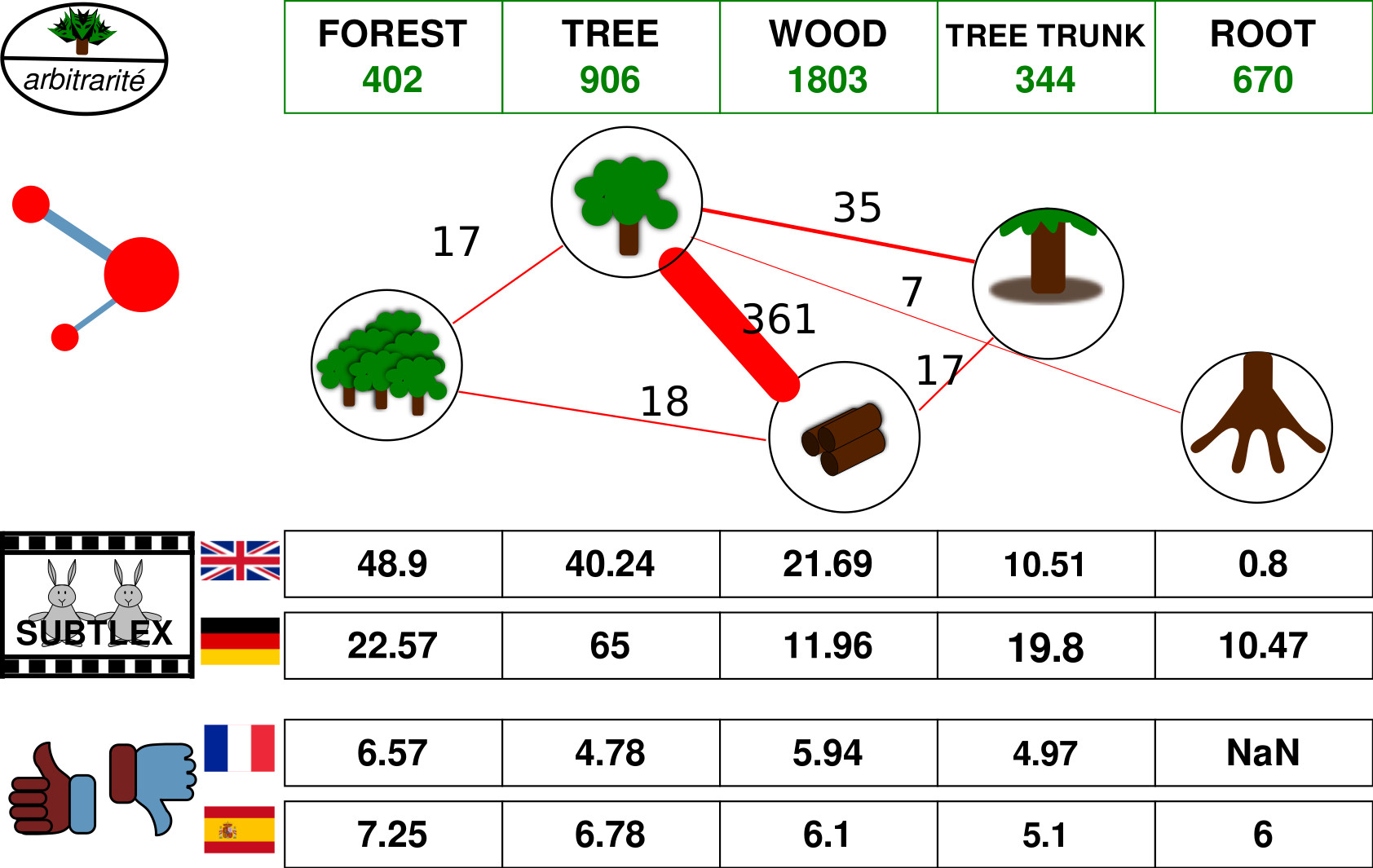
Expanding our Concepticon
Since our Concepticon resource offers a sophisticated way of handling concepts and words, we decided to use our test-driven data curation workflows to work towards a unification of various datasets for norms, ratings, and relations.
Examples
Norms, Ratings, and Relations
Workflow
- automatic linking of data
- manual refinement
- testing internal consistency
Examples
Norms, Ratings, and Relations
Examples
Norms, Ratings, and Relations
Statistics
NoRaRe (https://digling.org/norare/, Tjuka et al. 2022) now offers 98 datasets that themselves cover 65 unique properties for 40 languages.
We are working on expanding this further, and we hope that we can -- on the long run -- turn it into an authoritative repository for multilingual norm data in psychology, linguistics, and beyond.
Outlook

Outlook
- Linguistic constructs seem to be easy to handle, but they often give us a hard time.
- Reference catalogs have greatly improved our standardization attempts.
- Data curation workflows that involve test-driven data curation and targeted tools for annotation have helped a lot in assembling very large amounts of linguistic data.
- Now, we are in a situation where aggregated data can be actively used, and we start to be able to tackle concrete research questions that we could not tackle before.
- And, we want to know what else we could integrate?
Danke fürs Zuhören!
