A practical introduction to EDICTOR
A Web-Based Interactive Tool for Creating, Inspecting, Editing, and Publishing Etymological Datasets

Agenda 2020
- Introduction
- Getting Started
- Editing
- Analysis
- Customization
Introduction

Introduction
Computer-Assisted Langauge Comparison
- Traditional methods of historical linguistics are based on manual data annotation.
- With more data available, they reach their practical limits.
- Computational methods cannot replace experience and intution of experts.
Introduction
Computer-Assisted Langauge Comparison
- Since experts are slow, while computers are not very accurate, we need combined frameworks that reconcile classical and computational approaches.
- Computer-assisted language comparison may drastically increase the consistency of expert annotation while correcting for the lack of accuracy in computational analyses.
Introduction
Data and Models
- Data needs to be accessible in human- and machine-readable form.
- Data needs to be normalized, as far as this is possible.
- Models allow us to organize the data in a formal way.
- Software allows us to test if the data conforms to our model.
Introduction
Languages, Words, and Concepts
- Normally, people provide just a language name, assuming everybody knows what variety they talk about.
- Normally, people provide just a simple elicitation gloss, assuming everybody knows what they mean.
- Normally, people provide some kind of transcription or short cut, assuming that everybody knows how the words should be pronounced anyway.
Introduction
Languages
- Provide the language name in its original form, as you please (e.g.,
Mandarin (Běijīng)). - Provide the Glottocode in addition to your language name (e.g.
beij1234). - Provide a unique identifier for the language which does not contain brackets, accents, or any other characters not in ASCII range (e.g.,
BeijingMandarin).
Introduction
Concepts
- Use your original elicitation gloss, but make sure it is transparent (e.g., don't write
rain, writethe rainorrain (noun)). - Provide a link to the Concepticon project, if possible, if you don't find it, this is not a tragedy (e.g.,
658,RAIN (PRECIPITATION)). - You can search for elicitation glosses at https://digling.org/calc/concepticon.
Introduction
Words
- The word as you find it in a dictionary is your Value, you should never modify it from the original, where you find it (e.g., ZaoMin "mother" is given as
ni44; ʑe44in your data, soni44; ʑe44is your value). - If the entry has more than one word form, you should split them and list them separately, or list only one of them, this is your Form (
ni44; ʑe44thus becomesni44andʑe44). - The form is not computer-readable, as it must be normalized, to account for a transcription system that can be understood by a machine. So you need to segment it and convert it to the standards of the Cross-Linguistic Transcription Systems (
n i ⁴⁴andʑ e ⁴⁴).
Introduction
Wordlists
- A wordlist is usually thought of as a list consisting of a different language in each column and a different concept in each row, with word forms being placed in each cell. This format is not flexible and highly unpracticable.
- Our wordlist consists of a header, which indicates the values of the cells in each column, with the first column being reserved for a numeric ID.
- This is also known as "long table format", and all linguists should use it and abandon their traditional wordlist format.
Introduction
Wordlists

Typical linguistic data as illustrated in Wu et al. (2020).
Introduction
Wordlists

Long-table format, required for the EDICTOR as illustrated in Wu et al. (2020).
Introduction
EDICTOR
The EDICTOR (List 2017) is a web-based tool that allows to edit, analyse, and publish etymological data. It is available in Version 1.0. The tool can be accessed via the website at https://digling.org/edictor/. All that is needed to use the tool is a webbrowser (Firefox, Safari, Chrome). Offline usage is also possible, but requires to change webbrowser settings. The tool is file-based: input is not a database structure, but a plain tab-separated text file (as a single sheet from a spreadsheet editor in long table format). The data-formats are identical with those used by LingPy, thus allowing for a close interaction between automatic analysis and manual refinement.
Getting Started with the EDICTOR

Getting Started with the EDICTOR
What is the EDICTOR?
The EDICTOR is a web-based tool that allows to edit, analyse, and publish etymological data. It is available as a prototype in Version 0.1 and will be further developed in the project "Computer-Assisted Language Comparison" (2017-2021). The tool can be accessed via the website at http://edictor.digling.org, or be downloaded and used in offline form. All that is needed to use the tool is a webbrowser (Firefox, Safari, Chrome). Offline usage is currently restricted to Firefox. The tool is file-based: input is not a database structure, but a plain tab-separated text file (as a single sheet from a spreadsheet editor). The data-formats are identical with those used by LingPy, thus allowing for a close interaction between automatic analysis and manual refinement.
Getting Started with the EDICTOR
The Basic Structure of the EDICTOR
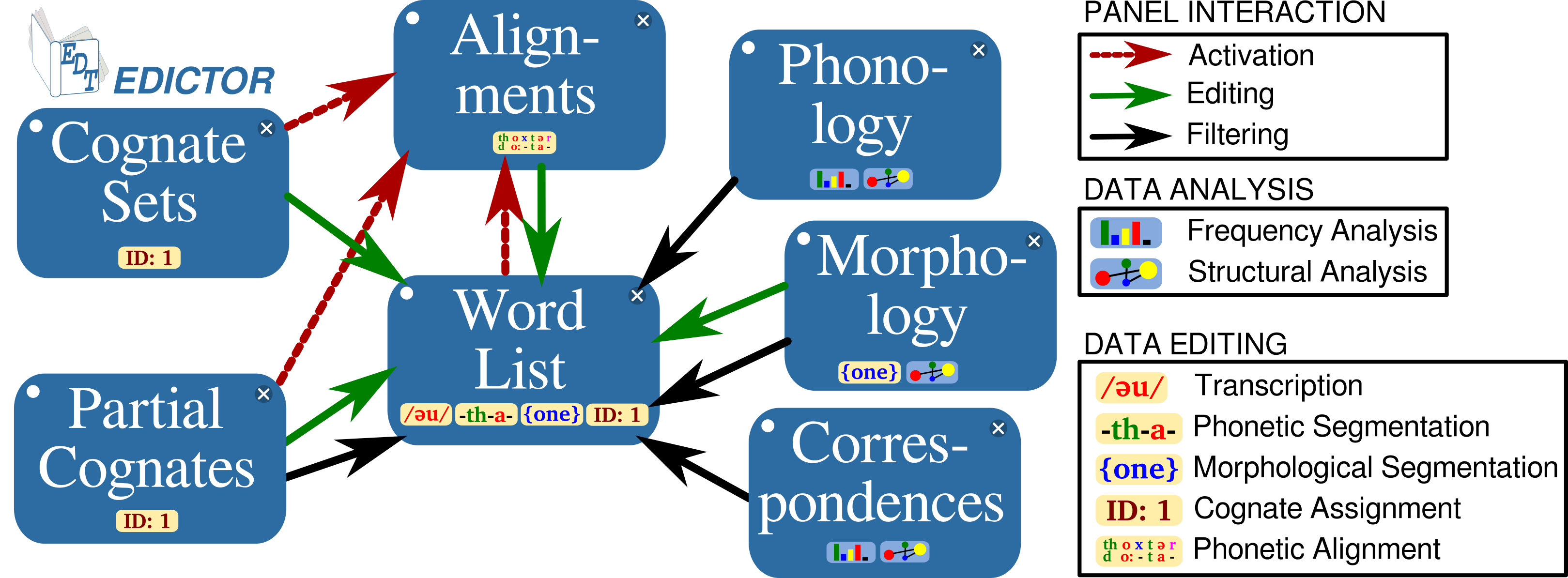
The EDICTOR structure is modular, consisting of different panels that allow for:
- data editing (data input, alignments, cognate identification)
- data analysis (phonological analysis, correspondence analysis)
- customisation
Getting Started with the EDICTOR
File Formats
File formats are straightforward:
- tab-separated values (easy to export from Excel and LibreOffice)
- one row corresponds to one word form, each word form needs a numerical ID
- specified headers for standardized columns (DOCULECT, CONCEPT, TRANSCRIPTION, basically customisable)

Getting Started with the EDICTOR
File Input and Output
- files are "uploaded" to the EDICTOR using the JavaScript file API (this is no real upload, as it is client-side, so no data will be transferred, but all data remains on the computer of the user)
- files are saved in local storage (will be lost if one closes the web-browser)
- files are downloaded to the computer (again, no real download from a remote server, but the act of saving data on the client computer in a file, using the new file API in HTML 5)
DEMO
Editing

Editing
Navigation
- navigation across the panels is straightforward by selecting which panels to show from a basic menu
- navigatin within the panels follows specific rules which may not be completely intuitive when testing the first time
- all panels have a help-tag that can be used to see the main features of a given panel
DEMO
Editing
Editing in the Wordlist Panel
- new rows can be added to a given input file, but this is not encouraged, instead, it is recommended to prepare a template containing the concepts which one wants to translateinto the target languages
- rudimentary support for the creation of customised questionnaires is provided (more support will be provided with the next official Concepticon release)
- SAMPA input for phonetic transcriptions is supported
- automatic segmentation of phonetic transcriptions is supported
- Pīnyīn input for Chinese characters is supported but not reliable yet
DEMO
Editing
Cognate Annotation (Cognate Panel)
Cognates can be assigned to words using two rudimentary operations:
- NEW: assign a new cognate set ID to the selected words
- COMBINE: combine the cognate set IDs of the selected words
The Cognates panel is synchronized with the wordlist panel: when assigning cognates within meaning slots, the wordlist panel is automatically filtered to show only the words under consideration.
The Cognates panel also allows to directly align the words which were assigned to the same cognate set.
DEMO
Editing
Partial Cognate Annotation (Partial Cognates Panel)
Partial cognates can be assigned to words provided that the data is segmented into morphemes. The assignment follows a very intuitive schema:
- from a bunch of words, morphemes are selected and then assigned to a new partial cognate ID
- words marked as cognate are shown in the same column, where they can be aligned
- clicking on the words in the column deletes them from the partial cognate sets
DEMO
Editing
Morpheme Annotation (Morphology Panel)
Annotating morpheme structures is an important first step for language-internal reconstruction, as it allows us to assign words in our data to word families. The EDICTOR offers a very innovative module that automatically searches for potential partial colexifications in morphologically presegmented data which can then be quickly annotated by an expert.
Editing
Morpheme Annotation (Morphology Panel)
The core idea of annotation is:
- the morphemes of a given word are annotated similar to glossed text in syntax annotations
- spaces serve as a separator between morpheme glosses, so morpheme glosses are not allowed to have spaces
- apart from that, the format is free, but identical strings in different words will be interpreted as actually cognate morphemes inside the language
DEMO
Analysis

Analysis
Phonology Analysis (Phonology Panel)
In order to check how well a given transcription was carried out, the Phonology panel can be used. It lists all phonemes for a given language (proper segmentation is required) and their frequency of occurrence. The expert can thus check the correctness of very rare phonemes or weird characters. Since the Phonology panel links to the Wordlist panel, experts can quickly find the words containing specific phonemes and correct them or inspect them. In addition, an IPA chart can be displayed to check the structural properties of the sound system of a given language.
DEMO
Analysis
Sound Correspondences (Correspondences Panel)
If alignments are provided for a given dataset, one can use the Correspondences Panel of the EDICTOR to compare the frequency of sound correspondences between language pairs. In this way, errors in cognate assignment or alignment analyses can be quickly corrected and a general idea regarding regular sound correspondences can be derived. Sound correspondences can also be defined for a given context. This needs to be submitted by the user as additional data in an additional column, or can be automatically computed, based on the idea of prosodic strings (List 2014) which assign each sound to a given value based on its prosodic weight.
DEMO
Analysis
Correspondence Patterns (Correspondence Patterns Panel)
You can also inspect correspondence patterns across all the languages in your sample, provided you have -- again -- completely aligned your data. A first method for correspondence pattern identification was proposed by List (2019), but the algorithm is time consuming and therefore only available in Python and you have to analyze your data with the algorithm and then load the file into the EDICTOR to inspect your data properly. However, the EDICTOR offers a very simple greedy solution that you can use for quick data inspection and which usually shows the most frequent patterns in your data.
DEMO
Analysis
Cognate Sets (Cognate Sets Panel)
Inspecting how the cognate sets are distributed in your data is very useful to get a direct impression into certain aspects of subgrouping. You can easily do this with help of the Cognate Sets panel of the EDICTOR. In addition, you can also export your data to the Nexus format from here and use the file in biological software packages, such as SplitsTree, to infer a quick tree or network.
DEMO
Customization
Customization
Templates
Templates can be used to develop first questionnaires that can then be filled out with help of the EDICTOR. Template functionality is still rudimentary in the EDICTOR. Users can select among different concept lists (Swadesh, Blust, etc.) and also merge multiple concept lists. More finegrained operations (the intersection of concept lists, or mergers which take concept similarity into account) are not yet implemented, but are currently developed for the Concepticon, where they will be available with the next official release (planned for 2017).
DEMO
Customization
Database Interface
The EDICTOR has a database backend that allows to store data automatically on a server. In order to support this, databases need to be explicitly created, and there is no official way to do this at the moment: Users who whish to use the database backend need to ask me to set up a database and create passwords for them. The interface for databases in the Customize menu allows to select those items of a given database, which users want to inspect. These are stored in a link that users can then bookmark and use whenever they want to work on the data.
DEMO
Customization
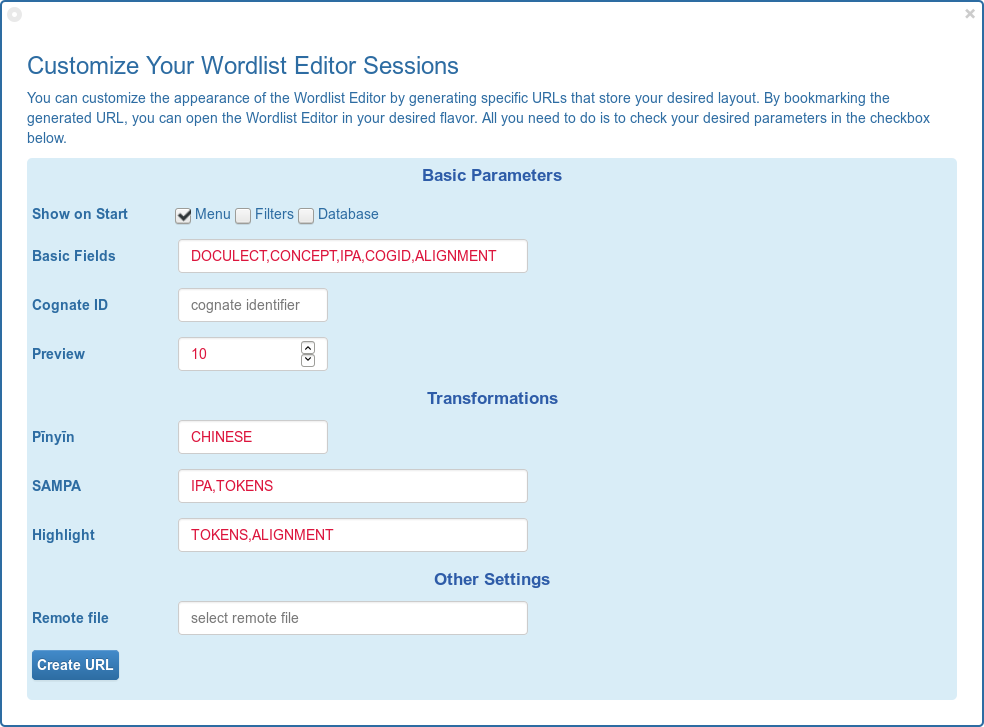
Custom Settings
Users can customize a great part of the EDICTOR's default settings. This is done with help of specific URLs that the user can bookmark to call the tool in their preferred view. For example, if one wants to see the alignments immediately when loading a file, this can be specified. If users prefer to use their own IPA keyboard instead of SAMPA conversion, this is also possible. More possibilities for customization will be added in the future, but already for the moment, the EDICTOR offers a great deal of flexibility.
DEMO
Customization
Publishing Data
The EDICTOR can also be used as a convenient interface to publish data in a nice form on the web. As it is purely text-based, all that is needed is to clone the EDICTOR software and host it on a server of one's choice. Then, by using customized URLs one can present a given dataset in read-only mode. In this way, users cannot edit the data, but they can use the interactive possibilities to inspect it.
Gracias a todos!