Three Open Problems in Computational Historical Linguistics

Agenda for the Talk
- Introduction
- Open Problems in Computational Historical Linguistics
- A Computer-Assisted Framework for Problem Solving
- 3 Problems and Possible Solutions
- Outlook
Introduction

Introduction
Problems
There Problems which we ignore:
La Société n'adment aucune communication concernant, soit l'origine du langage, soit la création d'une langue universelle. (Statuts de la Société de Linguistique de Paris, 1866: III)
Introduction
Problems
There are problems we did not know about:
The Proto-Sapiens grammar was so simple that the sporadic references in previous paragraphs have essentially described it. The prime importance of sound symbolism for the people of nature should be noted again before we further detail that the vowel “E” was felt as indicating the “yin” element, passivity, femininity etc. [...] (Papakitsos and Kenanidis 2018: 8)
Introduction
Problems
There are problems which we have forgotten:
Based on an analysis of the literature and a large scale crowdsourcing experiment, we estimate that an average 20-year-old native speaker of American English knows 42,000 lemmas and 4,200 non-transparent multiword expressions, derived from 11,100 word families. (Brysbaert et al. 2016: 1)
Introduction
Hilbert Problems
- 23 problems identified by the mathematician David Hilbert in 1900 (published in 1902)
- at least 10 problems have been solved by now
- some 7 problems have solutions which are accepted by some mathematicians
Introduction
Hilpert Problems
- Martin Hilpert proposed a list of problems for linguistics in a talk in 2014
- Russell Gray further promoted the idea of asking Hilpert questions for the field of diversity linguistics
Introduction
Problems for Computational Historical Linguistics
- "small" problems in comparison to the big questions asked by Hilpert and Gray
- all problems can be solved by some workflow or algorithm
- they may help us to advance our research in historical linguistics, since they may help us to formalize our work and to increase the data we can dispose of
Open Problems in CHL

Open Problems in CHL
Overview
- 10 problems in total
- basic division into problems of inference, simulation, statistics, and typology
- problems will be discussed on a monthly basis throughout 2019 on the blog The genealogical world of phylogenetic networks
- first two problems were already discussed in February and March
- general typology of problems: inference, modeling, analysis
Open Problems in CHL
Inference Problems
- 1 automatic morpheme segmentation (Blog in February 2019)
- 2 automatic sound law induction (Blog in March 2019)
- 3 automatic borrowing detection (Blog planned for April 2019)
- 4 automatic phonological reconstruction
Open Problems in CHL
Modeling Problems
- 5 simulation of lexical change
- 6 simulation of sound change
- 7 proof of language relatedness
Open Problems in CHL
Analysis Problems
- 8 typology of semantic change
- 9 typology of semantic promiscuity (List et al. 2016)
- 10 typology of sound change
Open Problems in CHL
Summary
In this talk, I will deal with three problems, namely the first three in my list:
- 1 automatic morpheme segmentation
- 2 automatic sound law induction
- 3 automatic borrowing detection
Problem Solving with CALC
![]()
Problem Solving with CALC
Computer-Assisted Language Comparison
- data in linguistics is steadily increasing
- our methods reach their practical limits, as they are tedious to apply
- we need to take computational methods into account
- but computational methods are not very accurate and may yield wrong results
Problem Solving with CALC
Computer-Assisted Language Comparison

Problem Solving with CALC
Machine Learning and Black Boxes
Big Data Promise:
"with enough data, we can solve all problems, and we do not even know in detail, how the problems should be solved, as the machine learning algorithms will figure out which parameters work best on their own" (The Average NLP Representative I met in the Past)
Problem Solving with CALC
Machine Learning and Black Boxes
How big data and machine learning works:
- create a dataset and measure different features (e.g., number of words in a text, number of bigrams, etc.)
- formulate the task as a decision question (e.g.: "is this a German text?", but not necessarily binary)
- feed the computer with annotated data in which the decisions are made by human experts
- use the trained model to solve more questions
Problem Solving with CALC
Machine Learning and Black Boxes
Problems of many machine learning frameworks:
- data is sparse in linguistics and humanities, but machine learning assumes that the data is big
- the features are poorly selected, without consulting experts and aiming for a careful modeling of what is already known to us
- results are a black box: they do not tell us how the internally selected features interact, or why a given output was produced after training the models
Problem Solving with CALC
Machine Learning and Black Boxes
Data sparseness:
- one million token corpora are nothing compared to what is used to have Google Translate provide at least approximately useful translations
- often, our linguistic data is restricted to wordlists of less than 500 words per language (but linguists can still squeeze out important signal from the data)
- our data is and never has been big in historical linguistics, but we have been able to develop methods to analyze the data anyway, yet our methods make use of more fine-grained models of the processes, which we lack in machine learning
Problem Solving with CALC
Machine Learning and Black Boxes
Feature design:
One of the promises of deep learning is that it vastly simplifies the feature-engineering process by allowing the model designer to specify a small set of core, basic, or “natural” features, and letting the trainable neural network architecture combine them into more meaningful higher-level features, or representations. However, one still needs to specify a suitable set of core features, and tie them to a suitable architecture. (Goldberg 2017: 18)
Problem Solving with CALC
Machine Learning and Black Boxes
Feature design:
- feature engineering or feature design (i.e.: modeling the processes we want to investigate) is largely ignored in most approaches (see Round 2017 for a linguistic account)
- scholars dream of a shortcut that allows them to infer something without going the hard way of figuring out how the processes actually work
- scholars at times criticize the use of "strong" models (as in our Python applications to cognate detection), since they are not "objective", but they misunderstand, that being objective does not require to be naive (t. b. c)
Problem Solving with CALC
Machine Learning and Black Boxes
The Black Box problem:
- since we do not know why trained models make the decisions they make, we have no way to learn from them (think of AlphaGo's success in Go: Go players now study the games by the machine to understand the strategies)
- since the models are trained on human annotations, the "objective" extraction of the most successful feature weights may as well reflect common human bias rather than scientific truth
- scientifically, a machine that tells us if two words are related or not is of no direct scientific value if we're interested in the deeper question of how we can prove word relatedness (it may be useful for other studies, but it does not solve scientific questions)
Problem Solving with CALC
Machine Learning and Black Boxes
The Black Box problem:

Lapuschkin et al. (2016)
Problem Solving with CALC
Machine Learning and Black Boxes
Summary
Be careful when using black-box approaches in your research, and ideally prefer transparent methods that make clear what they base their judgments on.
Problem Solving with CALC
Basic Aspects of Computer-Assisted Problem Solving
- within the CALC framework, we do not naively accept machine learning solutions, but we look for a careful inspection of the problems we actually want to solve
- we do not neglect machine learning approaches, and we use them where they seem to be useful (for example to clusters words to cognate sets ), but we neglect that all approaches only can have a solution based on Bayesian inference or neural networks, as it is nowadays often propagated
- we prefer explicit solutions about black box solutions (as a rule), and we require that one searches for an explicit solution before resorting to a machine-learning approach (nobody would tackle multiplication with neural networks)
Problem Solving with CALC
Basic Aspects of Computer-Assisted Problem Solving
Problem solving strategy:
- start from the qualitative solution(s) to the problem in linguistics
- describe the task in a precise and clearcut way, along with input data and output data
- try to model the process and to design a way to represent the data (do not hesitate to modify your original data model to require to know more about hte original data)
- seek for inspiration in neighboring disciplines and topics (graph theory, computer science, evolutionary biology) to come up with a solution for the problem
Problem Solving with CALC
Basic Aspects of Computer-Assisted Problem Solving
Summary:
- computer-assisted problem solving requires a good knowledge of classical historical linguistics
- it requires to discuss intensively with experts in order to formalize their intuition
- it requires a good knowledge of general solutions for problems (algorithmics) in different branches of science (specifically bioinformatics and graph theory)
3 Problems and Possible Solutions

3 Problems and Possible Solutions
Automatic Morpheme Segmentation
The task:
Given a list of less than 1000 words in phonetic transcription, readily segmented into sounds, with concepts mapped to common concept lists (e.g., Concepticon), identify the morpheme boundaries in the data.
3 Problems and Possible Solutions
Automatic Morpheme Segmentation
Current solutions:
- most algorithms build on n-grams (recurring symbol sequences of arbitrary length), assuming that n-grams representing meaning-building units should be distributed more frequently across the lexicon of a language, they assemble n-gram statistics from the data
- with Morfessor, there is a popular family of algorithms avilable in form of a stable library (Creutz and Lagus 2005, virpioja et al. 2013)
3 Problems and Possible Solutions
Automatic Morpheme Segmentation
How do current solutions perform?
- comparing the performance with the online Morfessor demo, we can see that the results are often disappointing
- even when being trained on large amounts of data, the algorithms do not seem to reach a high accuracy
- when being trained with less than 1000 words, they fail gloriously
3 Problems and Possible Solutions
Automatic Morpheme Segmentation

3 Problems and Possible Solutions
Automatic Morpheme Segmentation
Why is the task so difficult?
- morphemes are ambiguous, they are not only based on the form, but also on semantics
- even speakers may at times no longer understand the original morphology of their language (folk etymology, etc.)
3 Problems and Possible Solutions
Automatic Morpheme Segmentation
What do humans do to find morphemes?
- humans take semantics into account (e.g., compare Spanish hermano "brother" with hermana "sister")
- humans know that morphological structure varies across languages (compare SEA languages vs. Indo-European languages)
- humans try to infer phonotactic rules
- humans make use of cross-linguistic evidence
3 Problems and Possible Solutions
Automatic Morpheme Segmentation
Suggestions for solutions:
- employ semantic information (make use of resources, such as CLICS, Concepticon, etc.)
- employ phonotactic information (make use of the prosody models in LingPy)
- employ cross-linguistic information (use LingPy's sequence comparison techniques)
- give up the idea of a universal morpheme segmentation algorithm (rather proceed from linguistic areas)
- invest time to create datasets for testing and training
3 Problems and Possible Solutions
Automatic Contact Inference
The task:
Given word lists of different languages, find out which words have been borrowed, and also determine the direction of borrowing.
3 Problems and Possible Solutions
Automatic Contact Inference
Current solutions:
- conflicts in the phylogeny, explain them by invoking borrowings (MLN approach, Nelson-Sathi et al. 2011, List et al. 2014)
- similar words among unrelated languages (Mennecier et al. 2016)
- tree reconciliation methods (Willems et al. 2016)
- borrowability statistics (Sergey Yakhontov, as reported by Starostin 1990, Chén 1996, McMahon et al. 2005)
3 Problems and Possible Solutions
Automatic Contact Inference
How do current solutions perform?
- conflicts in the phylogeny tend to overestimate the amount of borrowing, since there are multiple reasons for conflicts in phylogenies, not only borrowing (Morrison 2011)
- sequence comparison on unrelated languages seem solid, but one needs to be careful with chance resemblances based on onomatopoetic words etc. (mama, papa, etc., Jakobson 1960)
- tree reconciliation methods are unrealistic if word trees are derived from simple edit distances
- sublist-approaches may be useful, but they require large accounts on known borrowings, which we usually lack
3 Problems and Possible Solutions
Automatic Contact Inference
Why is the task so difficult?
- detecting borrowing presupposes to exclude alternative reasons (inheritance, natural patterns, chance)
- no unified procedure for the identification of borrowings in the classical dispipline
- borrowing detection is much more based on multiple types of evidence than other disciplines
3 Problems and Possible Solutions
Automatic Contact Inference
What do humans do to find borrowings?
- search for phylogenetic conflicts (English mountain, French montagne)
- search for trait-related conflicts (German Damm, English dam)
- areal proximity (as a pre-condition)
- borrowability (in cases of doubt)
3 Problems and Possible Solutions
Automatic Contact Inference
Suggestions for solutions:
- increase cross-linguistic data in phonetic transcription and consistent definition of meanings to allow for search of similar words among unrelated languages
- test methods for automatic correspondence pattern recognition and search for trait-related conflicts (List 2019)
- work on cross-linguistic datasets of known borrowed words to increase our knowledge of borrowability
3 Problems and Possible Solutions
Automatic Sound Law Induction
The task:
Given a list of words in an ancestral language and their reflexes in a descendant language, identify the sound laws by which the ancestor can be converted into the descendant.
3 Problems and Possible Solutions
Automatic Sound Law Induction
Current solutions:
- simulation studies (black boxes, see e.g., Ciobanu and Dinu 2018) for word prediction
- manual tools to model sound change when providing sound laws (PHONO, Hartmann 2003)
3 Problems and Possible Solutions
Automatic Sound Law Induction
How do current solutions perform?
- problem of handling conditioning context (be it long-distance or abstract)
- no direct solution to the task at hand
3 Problems and Possible Solutions
Automatic Sound Law Induction
Why is the task so difficult?
- problem of handling context of arbitrary distance to target sound
- problem of handling "abstract" context (suprasegmentals)
- problem of handling systemic aspects of sound change (where sound change is modeled in features)
3 Problems and Possible Solutions
Automatic Sound Law Induction
Suggestions for solutions
- multi-tiered sequence modeling (List 2014, List and Chacon 2015)
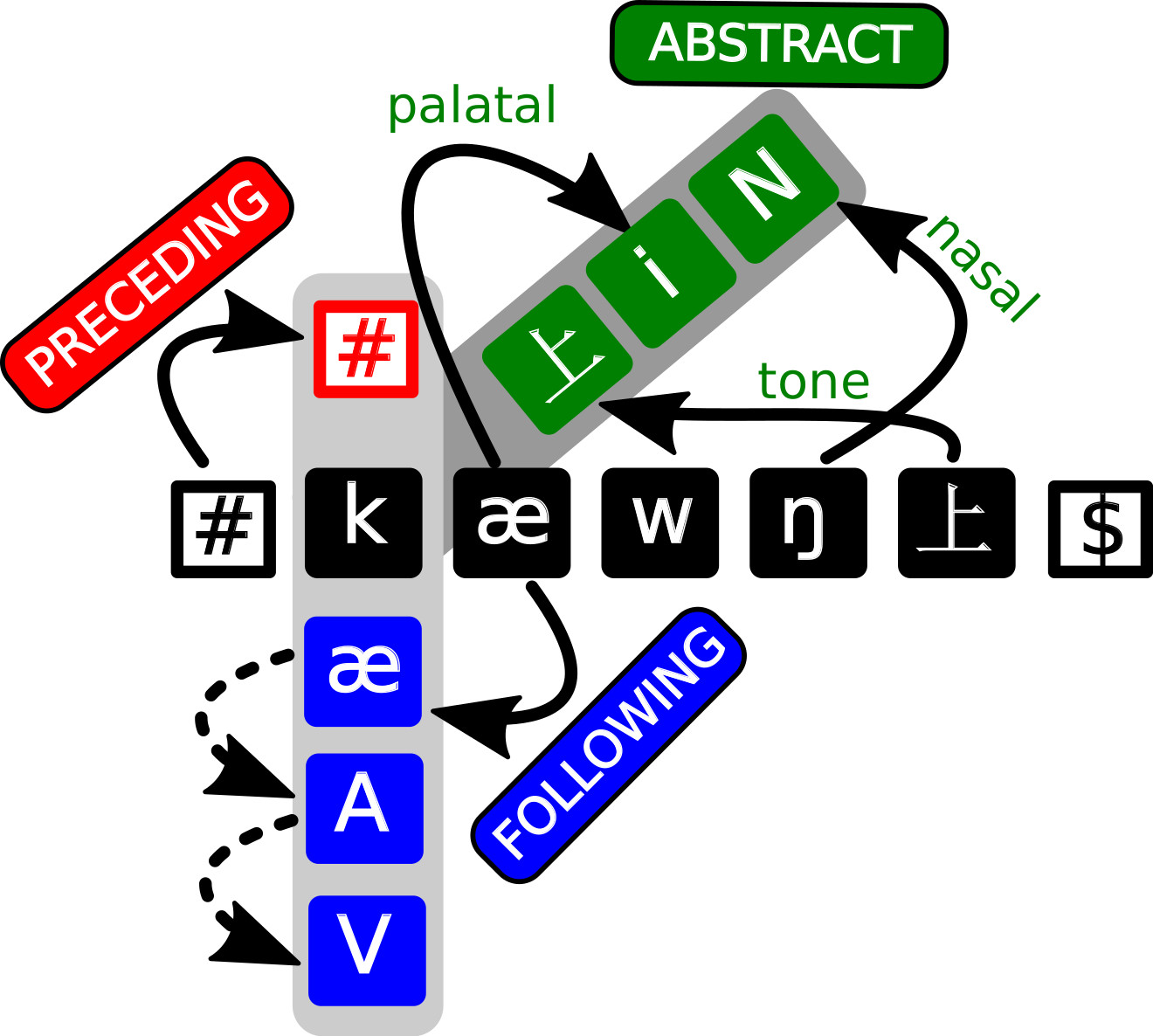
3 Problems and Possible Solutions
Automatic Sound Law Induction

3 Problems and Possible Solutions
Automatic Sound Law Induction

3 Problems and Possible Solutions
Automatic Sound Law Induction
- by modeling all different possible conditioning contexts, we make sure that we can find the context that conditions a sound change
- by selecting those which actually do condition a sound change, using computational tools, we can identify and propose potential environments of varying degrees of abstractness
- we still need, however, to reflect, how to handle systematic aspects of sound change
Outlook

Outlook
- we need to learn to state the problems in our field explicitly
- to address problems in computational historical linguistics, we need to start from solutions in classical historical linguistics
- applying a computer-assisted strategy for problem-solution can help to find solutions from which classical and computational aspects of linguistics profit
Спасибо за ваше внимание!
![]()