Computer-Assisted Approaches to Lexical Language Comparison
Reconciling Classical and Computational Approaches in Historical Linguistics
![]()
Introduction

Introduction
Classical Historical Linguistics
- Traditional methods of historical linguistics are based on manual data annotation.
- With more data available, they reach their practical limits.
Introduction
Computational Historical Linguistics
- Computational methods are fast and efficient, but not very accurate.
- Computational methods cannot replace experience and intution of experts.
Introduction
Computer-Assisted Language Comparison
- Since experts are slow, while computers are not very accurate, we need combined frameworks that reconcile classical and computational approaches.
- Computer-assisted language comparison may drastically increase the consistency of expert annotation while correcting for the lack of accuracy in computational analyses.

Cross-Linguistic Data Formats

Cross-Linguistic Data Formats
Background
The Cross-Linguistic Data Formats initiative (Forkel et al. 2016, http://cldf.clld.org) comes along with:
- standardization efforts (linguistic meta-data-bases like Glottolog, Concepticon, and CLTS)
- software APIs which help to test and use the data
- working examples for best practice
Cross-Linguistic Data Formats
Technical Aspects
- See http://github.com/glottobank/cldf for details, discussions, and working examples.
- Format for machine-readable specification is CSV with metadata in JSON, following the W3C’s Model for Tabular Data and Metadata on the Web (http://www.w3.org/TR/tabular-data-model/).
- CLDF ontology builds and expands upon the General Ontology for Linguistic Description (GOLD).
- pcldf API in Python is close to first release and can be used to test datasets whether they conform to CLDF
Cross-Linguistic Data Formats
Standards
- Wordlist standard (integrated into various tools like LingPy, Beastling, and EDICTOR)
- Dictionary standard (will be the basic for the Dictionaria project, http://dictionaria.clld.org)
- Feature standard (basic ways to handle grammatical features in cross-linguistic datasets)
Cross-Linguistic Data Formats
Standards: Examples

Forkel et al., Nature Scientific Data, to appear
Cross-Linguistic Data Formats
Standards: Examples

Forkel et al., Nature Scientific Data, to appear
Cross-Linguistic Data Formats
Reference Catalogs
- Concepticon (List et al. 2016) handles concepts across different datasets and questionnaires.
- Glottolog (Hammarström et al. 2017) helps to handle languages via unique identifiers.
- CLTS (Anderson et al. under review) is supposed to provide the missing standard for the handling of phonetic transcription systems by providing unique identifiers across distinct sounds which can be found across linguistic datasets
http://cldf.clld.org
Concepticon

Concepticon
Introduction
[...] it is a well known fact that certain types of morphemes are relatively stable. Pro- nouns and numerals, for example, are occasionally replaced either by other forms from the same language or by borrowed elements, but such replacement is rare. The same is more or less true of other everyday expressions connected with concepts and ex- periences common to all human groups or to the groups living in a given part of the world during a given epoch. (Swadesh 1950: 157)
Concepticon
Introduction
I, thou, he, we, ye, one, two, three, four, five, six, seven, eight, nine, ten, hundred, all, animal, ashes, back, bad, bark, belly, big, [...] this, tongue, tooth, tree, warm, water, what, where, white, who, wife, wind, woman, year, yellow. (ibid.: 161)
Concepticon
Concept Lists

Concepticon
Linking Concept Lists
- concepts labels in each concept list are linked to concept sets
- concept sets are further linked to metadata
- concept sets are linked to each other via a rudmentary concept hierarchy
Concepticon
Linking Concept Lists

Concepticon
Examples
- not all concepts are easy to link
- sometimes, scholars change the meaning of their "basic concepts" slightly across the years, but this is not often noticed by the experts in the field
- sometimes scholars also say that their concept list is identical to a given one, but after inspection it turns out that this is not the case
Concepticon
Examples

Concepticon
Outlook
Forthcoming Concepticon version (1.1) features:
- enhanced API that facilitates the task of automatic concept linking
- many more concept lists
- many more concepts
- more metadata
http://concepticon.clld.org
CLTS

CLTS
Background
- North American Phonetic Alphabet
- International Phonetic Alphabet
- Uralic Phonetic Alphabet
- Teutonista
- Sinologists, Africanologists, Americanologists, ...
CLTS
Problems
- "IPA inside" may mean different things
- "IPA" itself creates ambiguities
- "IPA" is not a standard, as it does not provide evaluation tools, but instead a set of suggestions
- "IPA" suggestions are disregarded and ignored by linguists in multiple ways
- see Moran and Cysouw (2018) for details on Unicode and IPA pitfalls...
CLTS
Comparative Databases
- Ruhlen's (2008) Global linguistic database (written in NAPA with modifications)
- Starostin's Global Lexicostatistical Database (unified transcription system, which deviates from IPA)
- Mielke's (2008) PBase, a database of phonological patterns, uses IPA (with some modifications and inconsistencies)
- Phoible (Moran et al. 2015), a database of phoneme inventories, uses IPA (with some modifications and inconsistencies)
- The IPA regularly publishes (now also digitally) its Illustrations of the IPA which should be the standard, but are not formally tested
CLTS
Comparative Databases
- Wikipedia has a large collection of Language phonologies in which the IPA is supposed used, but which are not formally tested
- field workers all of the world produce data in transcriptions that are supposed to conform to the IPA, but they often largely differ regarding their respective strictness of adhering to IPA
- the ASJP project designed a short alphabet to gather rough transcriptions of lexical items of different languages of the world
- Fonetikode (Dediu and Moisik 2016) is an attempt to link Ruhlen's and Phoible's sounds to a new feature system, but they do not use the original Ruhlen data and do not provide annotations for all symbols
CLTS
Comparative Databases
| Dataset | Transcr. Syst. | Sounds |
|---|---|---|
| GLD (Ruhlen 2008) | NAPA (modified) | 600+ (?) |
| Phoible (Moran et al. 2015) | IPA (specified) | 2000+ |
| GLD (Starostin 2015) | UTS | ? |
| ASJP (Wichmann et al. 2016) | ASJP Code | 700+ |
| PBase (Mielke 2008) | IPA (specified) | 1000+ |
| Wikipedia | IPA (unspecified) | ? |
| JIPA | IPA (norm?) | 800+ |
Cross-Linguistic Transcriptions
Objectives
- provide a standard for phonetic transcription for the purpose of cross-linguistic studies
- standardized ways to represent sound values serve as "comparative concepts" in the sense of Haspelmath (2010)
- similar to the Concepticon, we want to allow to register different transcription systems but link them with each other by linking each transcription system to unique sound segments
Cross-Linguistic Transcriptions
Objectives
- in contrast to Phoible or other databases which list solely the inventories of languages, CLTS is supposed to serve as a standard for the handling of lexical data in the CLDF framework, as a result, not only sound segments need to be included in the framework, but also ways to transcribe lexical data consistently
Cross-Linguistic Transcriptions
Strategy
- register transcription systems by linking the sounds to phonetic feature bundles which serve as identifier for sound segments
- apply a three-step normalization procedure that goes from (1) NFD-normalization (Unicode decomposed characters), (2) via Unicode confusables normalization, to (3) dedicated Alias symbols
- divide sounds in different sound classes (vowel, stop, diphthong, cluster, click, tone) to define specific rules for their respective feature sets
Cross-Linguistic Transcriptions
Strategy
- allow for a quick expansion of the set of features and the sound segments for each alphabet by applying a procedure that tries to guess unknown sounds by decomposing them into base sounds and diacritics
- use the feature bundles and the different transcription systems to link the transcription systems with various datasets, like Phoible, LingPy's sound class system, Wikipedia's sound descriptions, or the binary feature systems published along with PBase
- features are not ambitious in the sense of being minimal, ordered, exclusive, binary, etc., but serve as a means of description, following the IPA as closely as possible
Cross-Linguistic Transcriptions
Strategy
- be greedy: create many possible sounds, even if they are not attested, to make sure that if a given source contains them, that they are already there
- be explicit (to some degree): if sounds are generated, and scholars annotate certain sounds, even if it seems that they are unpronouncable, analyze them anyway,
Cross-Linguistic Transcriptions
Examples: Three-Step-Normalization
| In | NFD | Confus. | Alias | Out |
|---|---|---|---|---|
| ã (U+00E3) | a (U+0061) ◌̃ (U+0303) | ã | ||
| a (U+0061) : (U+003a) | a (U+0061) ː (U+02d0) | aː | ||
| ʦ (U+02a6) | t (U+0074) s (U+0073) | ts |
Cross-Linguistic Transcriptions
Examples: Three-Step-Normalization
| In | Identifier |
|---|---|
| ã | nasalized unrounded open front vowel |
| aː | long unrounded open front |
| ts | voiceless alveolar affricate stop |
CLTS
Statistics
- 15 transcription datasets
- 17403 Graphemes
- 15090 covered in the CLTS system
- 7404 unique CLTS graphemes (!)
- 87% average coverage of graphemes represented in CTLS on average
http://calc.digling.org/clts/
Cognate Detection and Annotation

Cognate Detection and Annotation
Introduction
- Software is needed to preprocess the data, so that it can later be quickly corrected by a human expert.
- For many purposes, current algorithms are good enough to provide real help in data-preprocessing.
Cognate Detection and Annotation
Introduction
LingPy: Python library for quantitative tasks in historical linguistics offers many methods for sequence comparison (phonetic alignment, cognate detection), phylogenetic reconstruction, ancestral state reconstruction, etc. * can read CLDF files
Cognate Detection and Annotation
Automatic Cognate Detection

Cognate Detection and Annotation
Automatic Cognate Detection: Performance
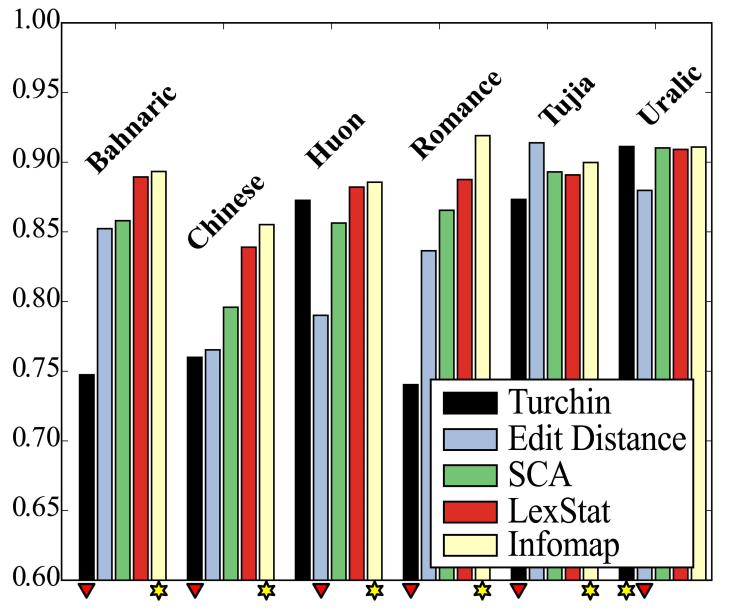
List, Greenhill, and Gray, PLOS ONE, 2017
Cognate Detection and Annotation
Automatic Cognate Detection: Performance
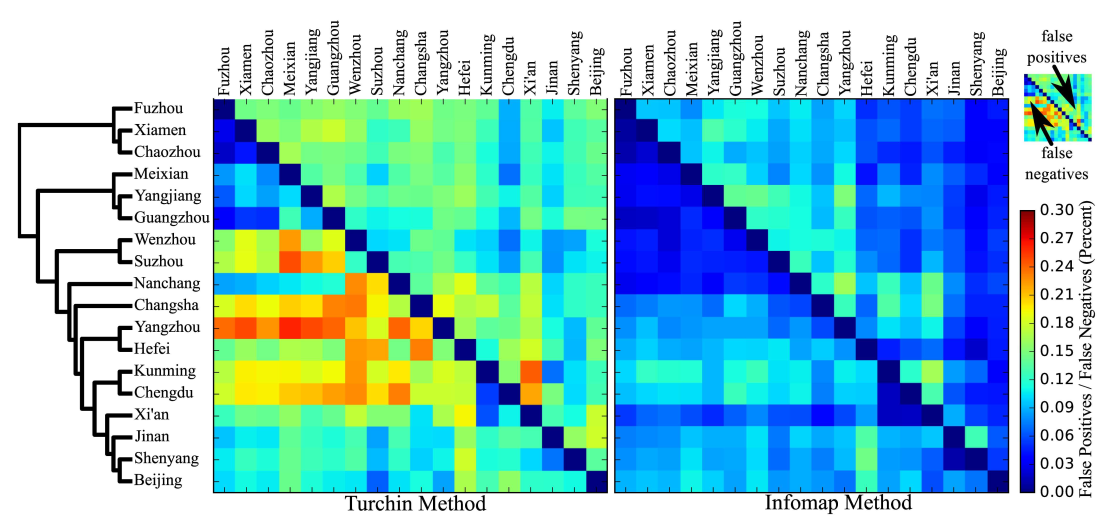
List, Greenhill, and Gray, PLOS ONE, 2017
Cognate Detection and Annotation
Automatic Cognate Detection: Performance
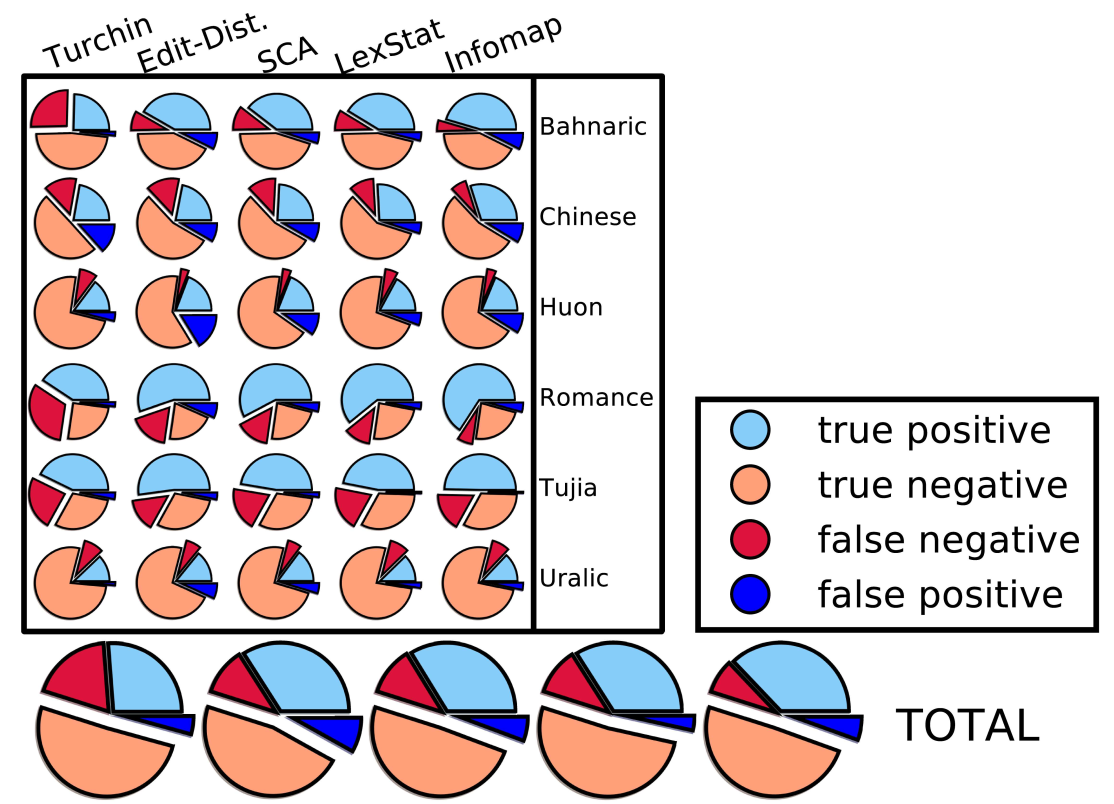
List, Greenhill, and Gray, PLOS ONE, 2017
Cognate Detection and Annotation
Cognate Annotation with EDICTOR
The EDICTOR is a web-based tool that allows to edit, analyse, and publish etymological data. It is available as a prototype in Version 0.1 and will be further developed in the project "Computer-Assisted Language Comparison" (2017-2021). The tool can be accessed via the website at http://edictor.digling.org, or be downloaded and used in offline form. All that is needed to use the tool is a webbrowser (Firefox, Safari, Chrome). Offline usage is currently restricted to Firefox. The tool is file-based: input is not a database structure, but a plain tab-separated text file (as a single sheet from a spreadsheet editor). The data-formats are identical with those used by LingPy, thus allowing for a close interaction between automatic analysis and manual refinement.
Cognate Detection and Annotation
Structure of the EDICTOR
The EDICTOR structure is modular, consisting of different panels that allow for:
- data editing (data input, alignments, cognate identification)
- data analysis (phonological analysis, correspondence analysis)
- customisation
EDICTOR.DIGLING.ORG
Cognate Detection and Annotation
EDICTOR Demo for Mapudungun and Quechua
- data from the Sound Comparisons Project (Heggarty et al. in progress, http://soundcomparisons.com)
- data prepared by Ludger Paschen, recordings done by Paul Heggarty, Scott Sadowsky and Maria-José Aninao, transcriptions done by Scott Sadowsky and Lewis Lawyer
- examples illustrate the usefulness of alignment analyses, as well as challenges involved with aligning words containing, for example, less "regular" instances of sound change, like metathesis
CLICS

CLICS
Polysemy, Homophony, Colexification
- Polysemy:
- If a word has two or more meanings which are historically related.
- Homophony:
- If two words which do not share a common etymological history have an identical pronunciation.
- Colexification (coined by François 2008):
- If one word form denotes several meanings.
CLICS
Colexification Networks
| Key | Concept | Russian | German | ... |
|---|---|---|---|---|
| 1.1 | world | mir, svet | Welt | ... |
| 1.21 | earth, land | zemlja | Erde, Land | ... |
| 1.212 | ground, soil | počva | Erde, Boden | ... |
| 1.420 | tree | derevo | Baum | ... |
| 1.430 | wood | derevo | Holz | ... |
CLICS
Colexification Networks
- concepts are represented as nodes in a colexification network.
- instances of colexification in the languages are represented as links between the nodes
- edge weights in the network reflect the number of attested instances of a given colexification or the number of languages or language families in which the colexification occured
CLICS
Analysing Colexification Networks

CLICS
Analysing Colexification Networks

CLICS
CLICS¹ Database
CLICS (List et al. 2014) was an online database of synchronic lexical associations ("colexifications") in 221 language varieties of the world.
CLICS
CLICS¹ Database
Database of Cross-Linguistic Colexifications (CLICS):
- CLICS¹ offered information on colexification in 221 different languages.
- 301,498 words covering 1,280 different concepts
- 45,667 cases of colexification, identified with help of a strictly automatic procedure, correspond to 16,239 different links between the 1,280 concepts in CLICS
CLICS
CLICS² Database
Problems of CLICS¹
- difficult to curate
- difficult to correct
- difficult to use computationally
- difficult to re-use by the community for similar projects
- difficult to expand (only three sources, only 221 languages)
CLICS
CLICS² Database
Basic ideas for CLICS²
- use CLDF as basic format for representation
- link many different datasets to Concepticon and Glottolog and store them as CLDF
- make a new CLICS application with a transparent Python API
- separate data, data analysis, and data deployment
- create a CLLD application for easy deployment of the data
CLICS
CLICS² Database
Results for CLICS² (List et al. 2018)
- more than 1000 languages
- more than 1500 concepts
- full replicability with the clics2 Python API (https://github.com/clics/clics2)
- sources of CLICS² (15 different datasets) are fully traceable
- new web application more beautiful than before
- old "look-and-feel" is preserved thanks to a standalone application that runs on every server based on pure JavaScript
CLICS
CLICS Database
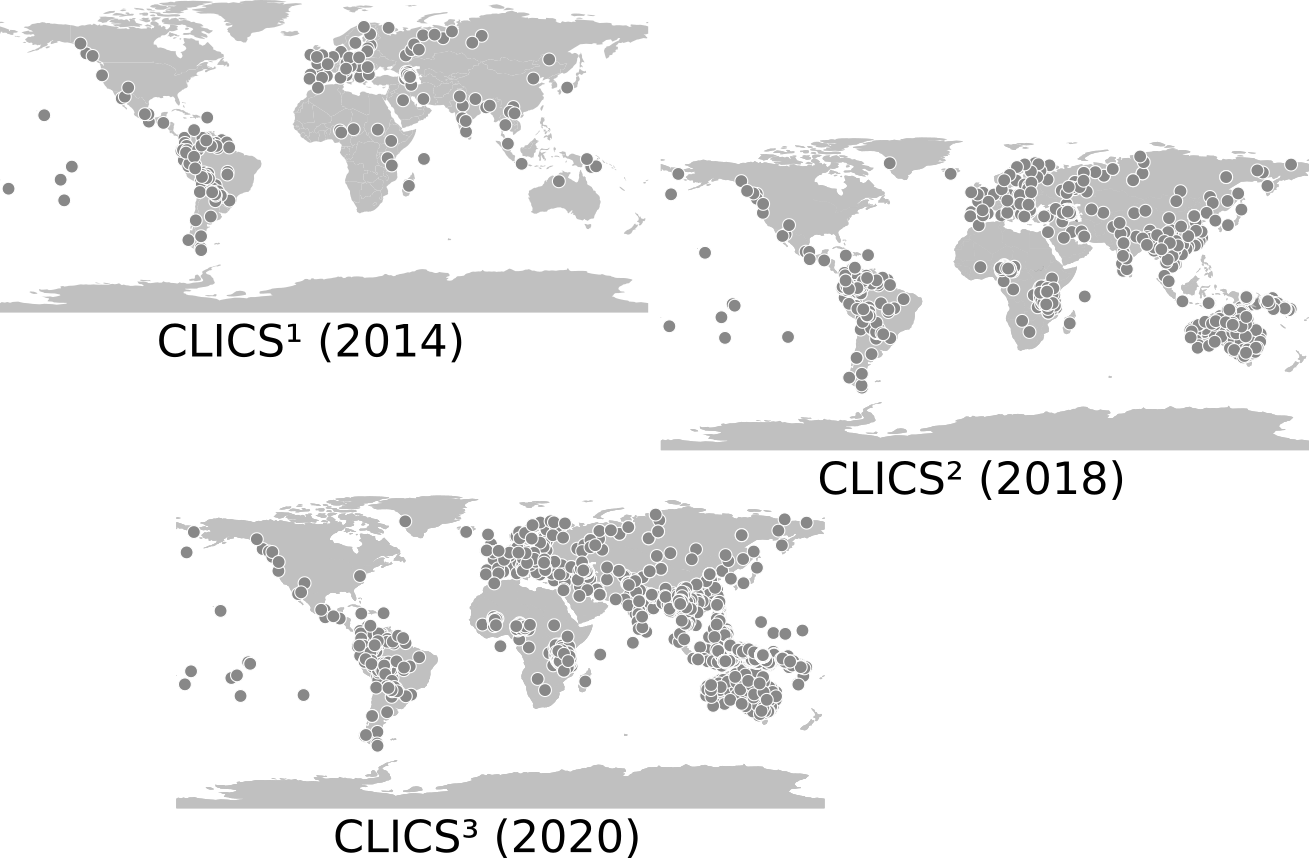
CLICS², Linguistic Typology, List et al. 2018
CLICS.CLLD.ORG
LINGPY.ORG
Outlook

Outlook
Imagine...
- ... that every publication based on data would submit this in comparable standards
- ... that these standards would be controlled by the community and people would see it as an honor to adhere to standards
- ... that all wordlists that have been published are linked to Concepticon and accounted for by Glottolog
- ... that somebody who wants to know anything about any language in the world could obtain the relevant data in machine- and human-readable form by searching a single website
- ... that scholars world-wide would collaborate to improve the standard and facilitate its use
Outlook
Preliminary ideas: Lexibank
Lexibank is planned to function as
- a repository for datasets (similar ot gene bank in biology) in CLDF format (currently mostly lexical data, but feature data sets are also possible)
- a semi-automatic system to check whether the data adheres to the CLDF standards
- a rating system for the completeness of the data
- a software API that helps to manipulate the data and convert it to multiple formats
- a cookbook series of tutorials that illustrate how the data can be used and analysed with computational tools
github.com/lexibank
¡Gracias a todos!
