Sequence Comparison with LingPy
A Computer-Assisted Approach

Agenda 2017
- Introduction (WHAT?)
- Benefits of Sequence Comparison (WHY?)
- Automatic Sequence Comparison (HOW?)
- Data (Formats, Representation, Checking)
- Methods (Workflow, Theory)
- Analysis (Practice, Interpretation, Further Use)
- Outlook
Introduction
Introduction
Sequences
Given an alphabet (a non-empty finite set, whose elements are called characters), a sequence is an ordered list of characters drawn from the alphabet. The elements of sequences are called segments. The length of a sequence is the number of its segments, and the cardinality of a sequence is the number its unique segments. (cf. Böckenbauer and Bongartz 2003: 30f)
Introduction
Sequences

Introduction
Sound Sequences
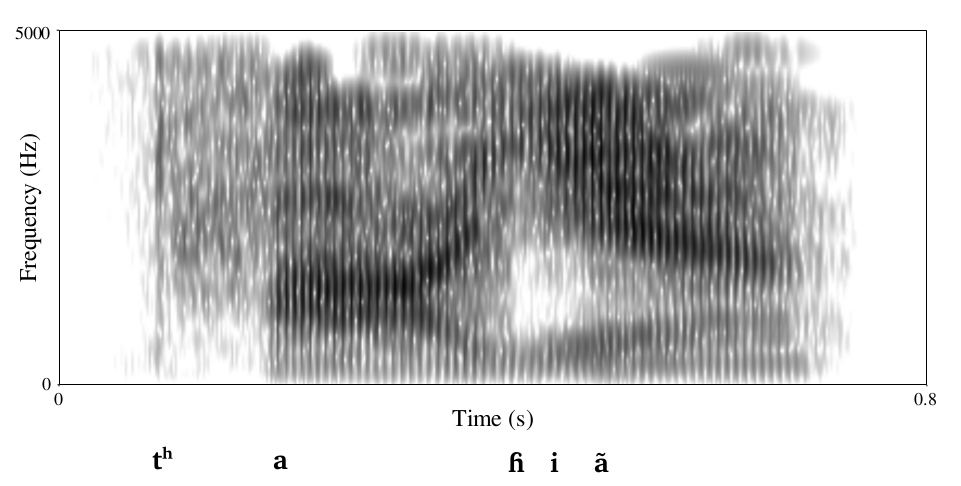
Introduction
Alignments
Introduction
Sound Change
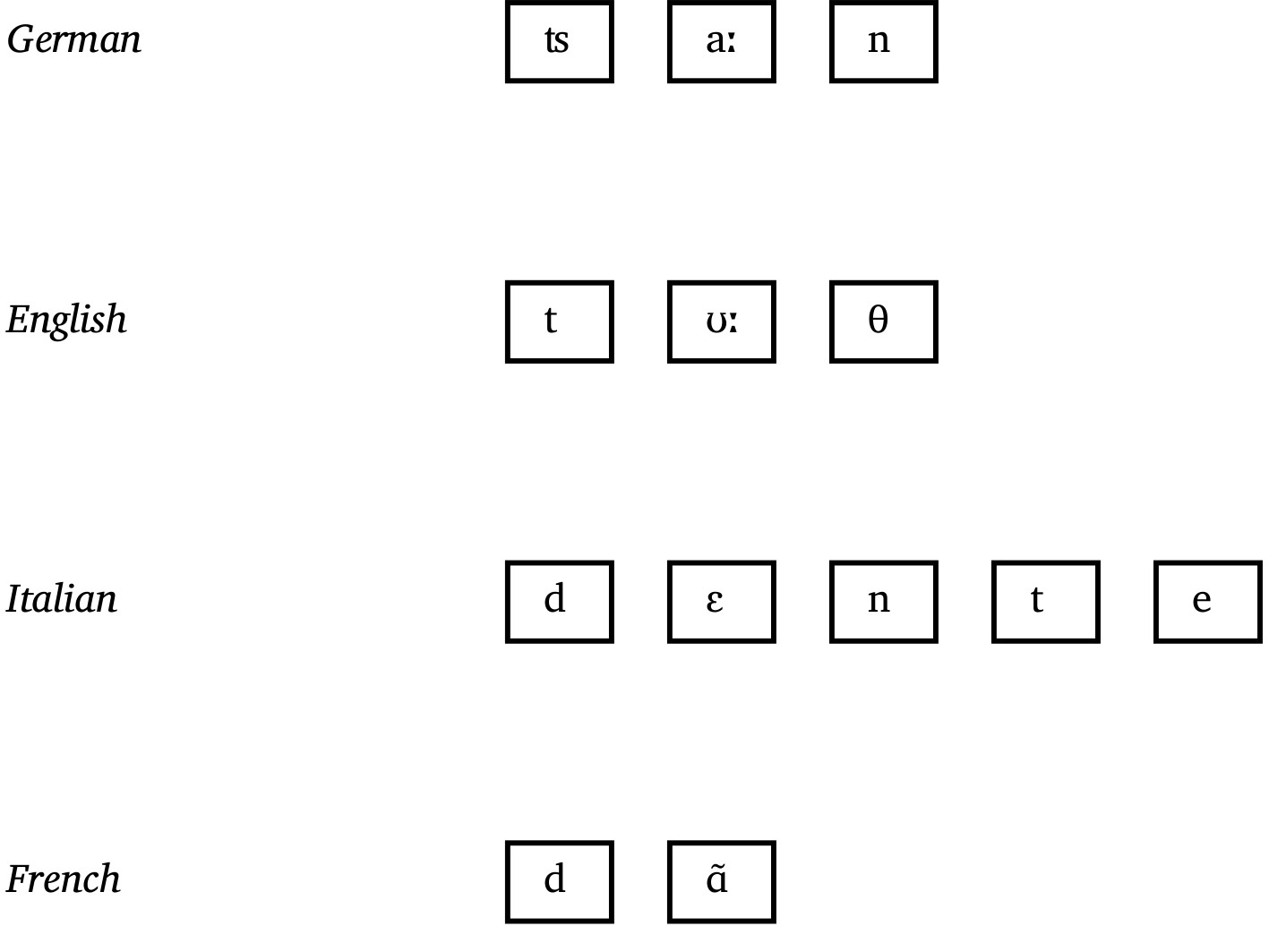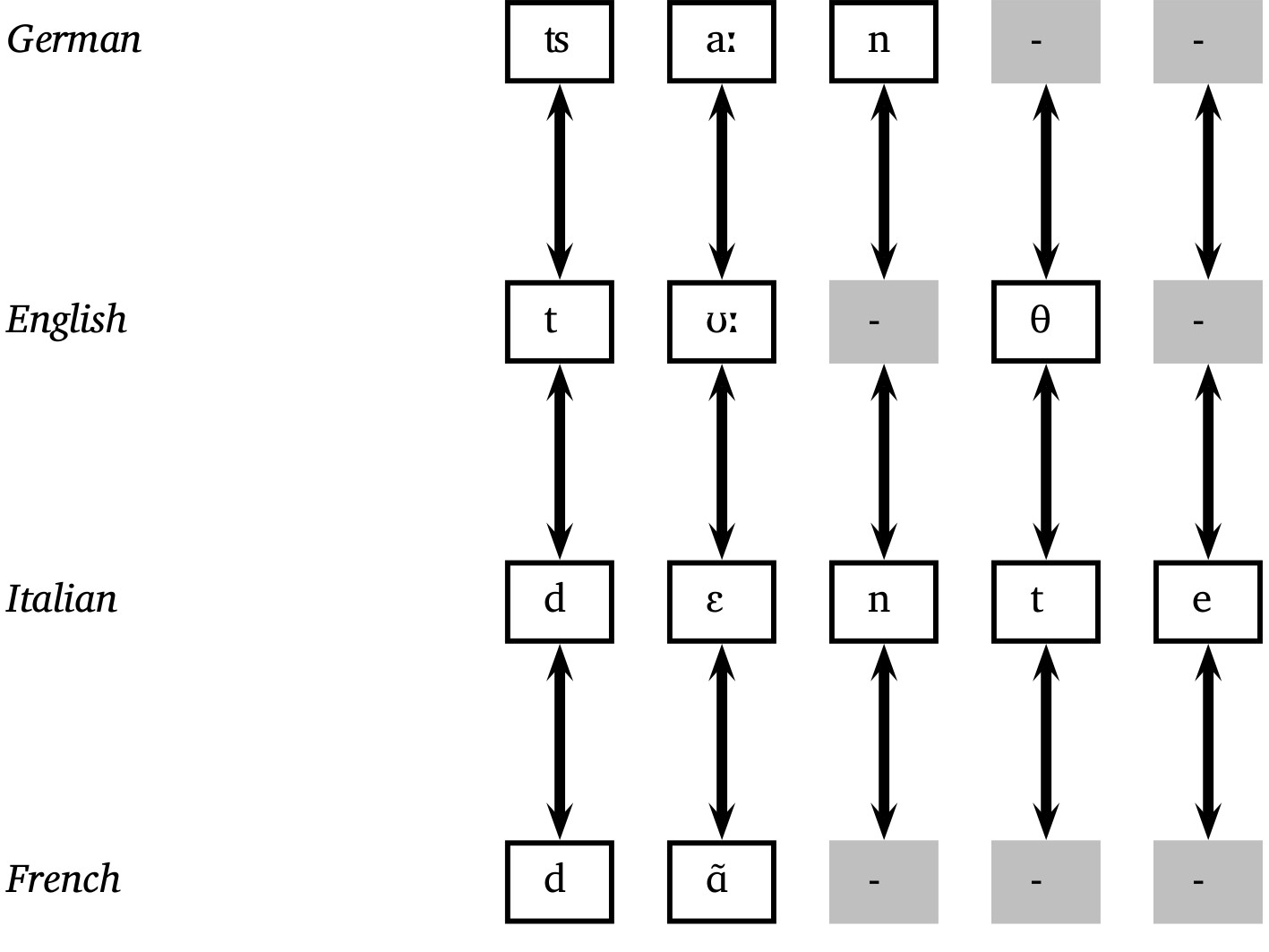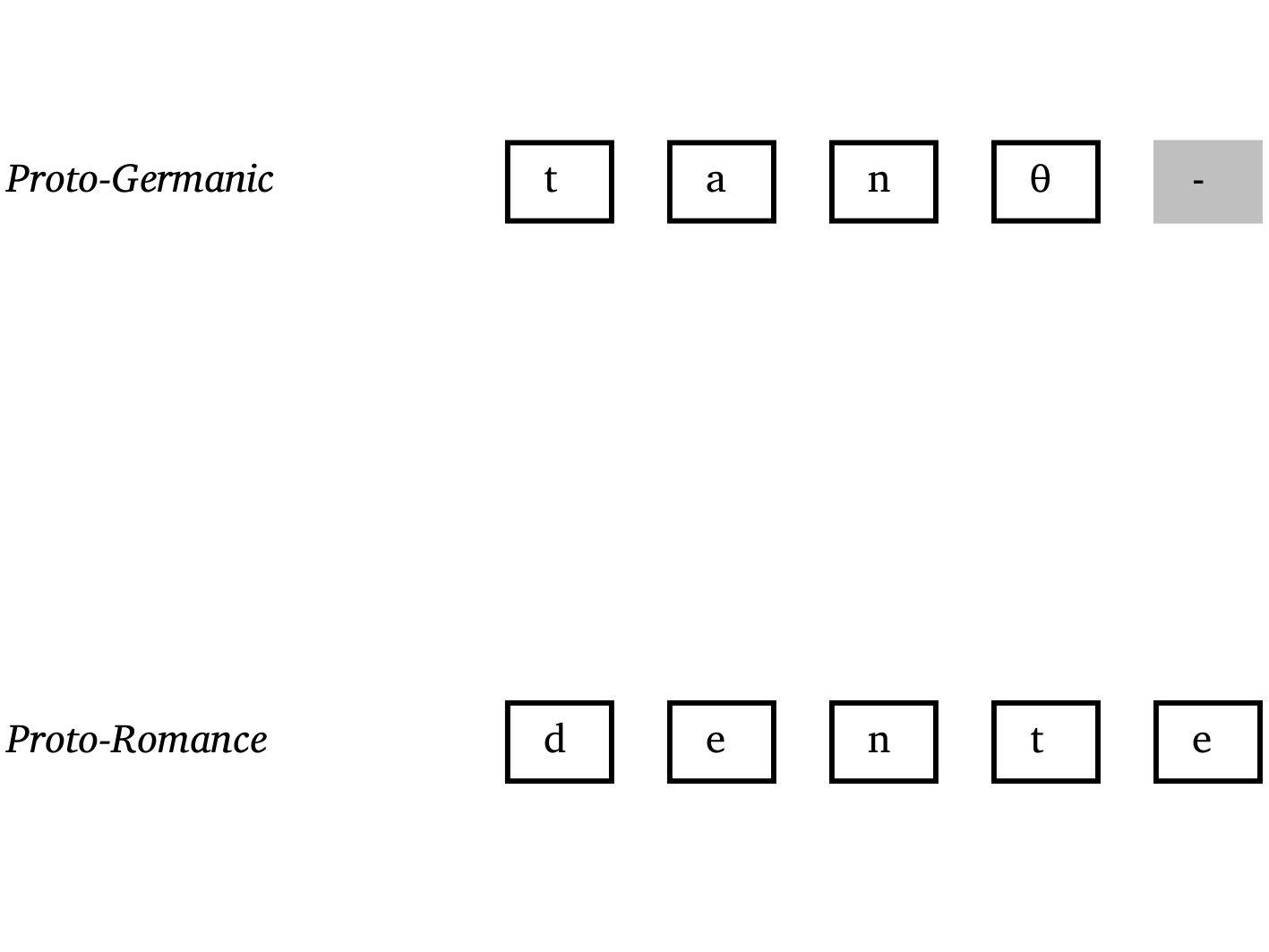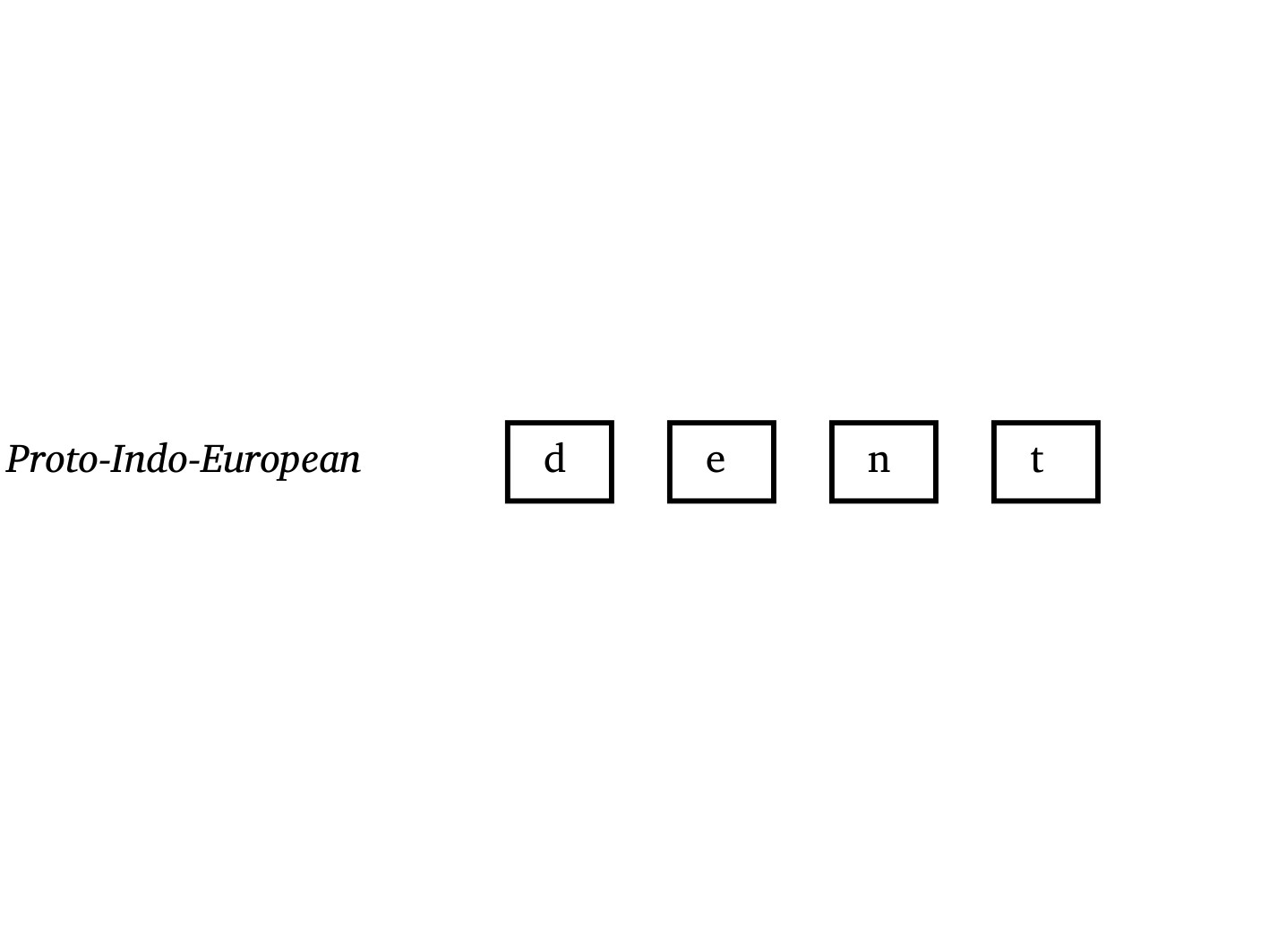
Introduction
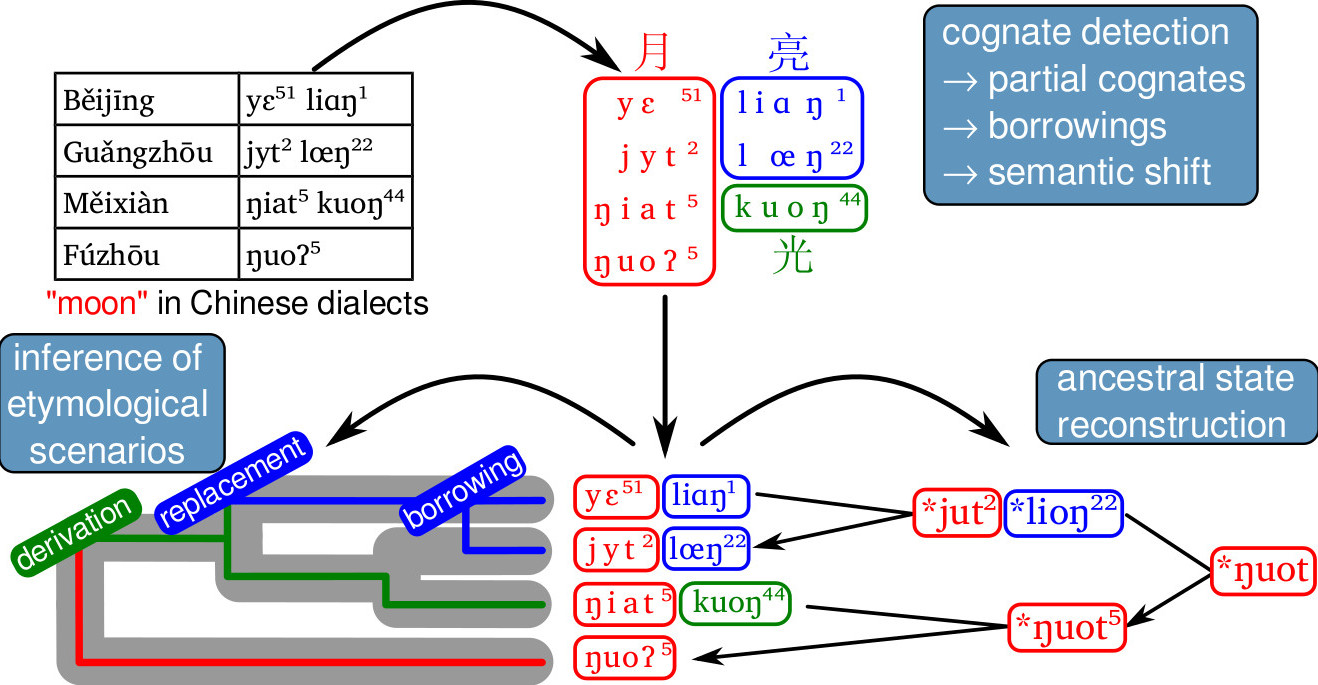
Cognacy
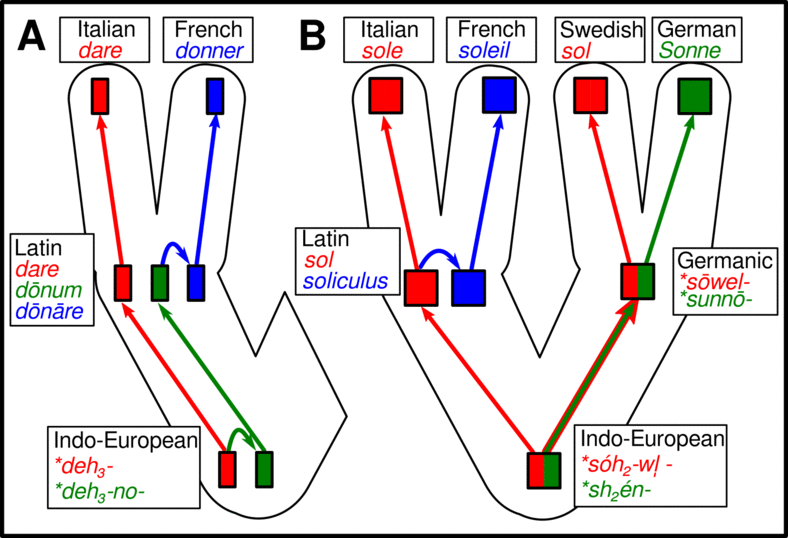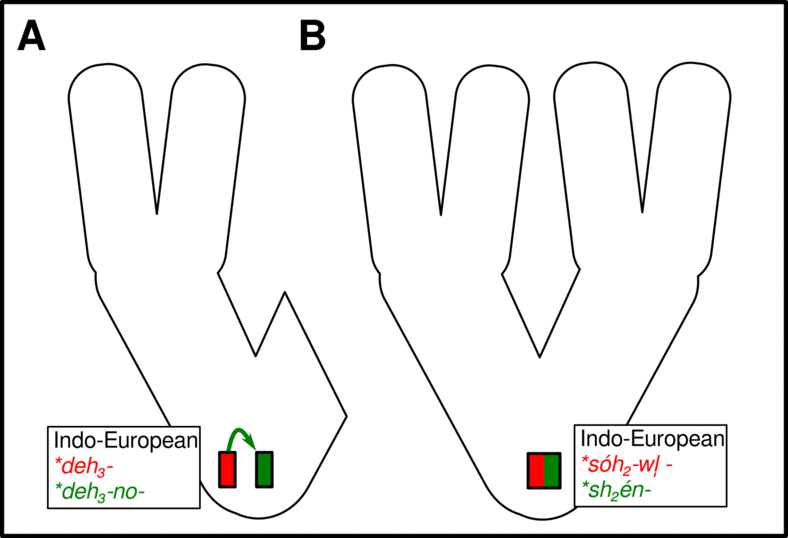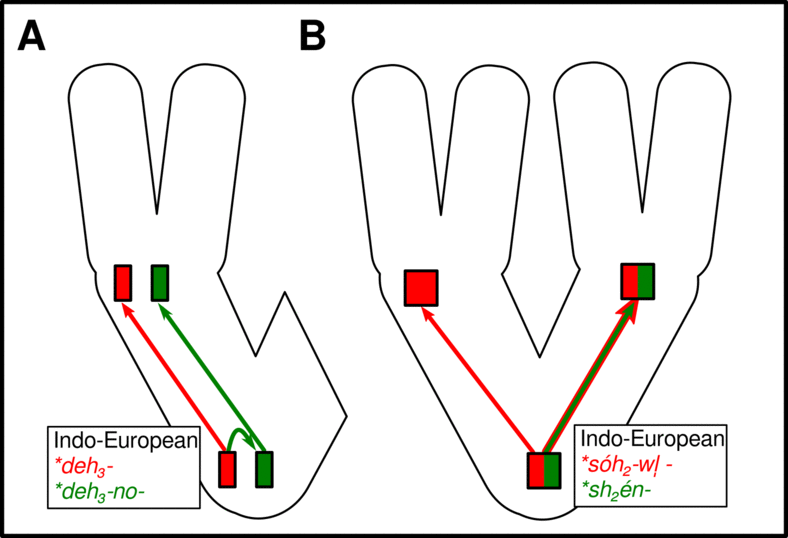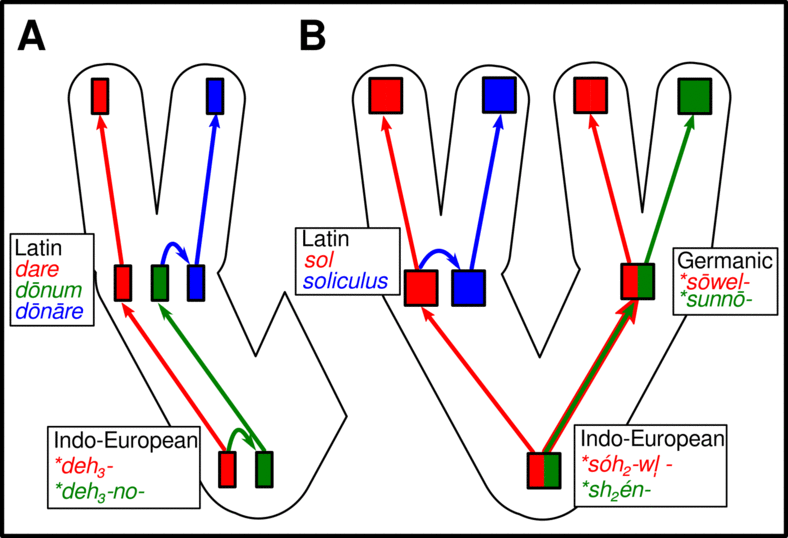
Introduction
Comparative Methods

Introduction
Summary
Sequence comparison plays a crucial role in historical linguistics. Despite this role, however, scholars working in an exclusively qualitative paradigm barely consider the importance of segmentation and alignments in their work, and although they implicitly use alignments, they often even neglect them when being asked to make them explicit.
Benefits

Benefits
Avoid Errors
Automatic sequence comparison cannot yet compete with trained linguists. Linguists, however, are human, which means that they necessarily make errors, sooner or later (before or after lunch). Using computational techniques for cautomatic cognate detection may reveal these inconsistencies and help the annotators to improve their data.
Benefits
Explore Data
We do not have annotated data for all languages in the world. Before starting to collect them, we may want to explore data for which no cognate judgmnets exist. This can help us to:
- identify major subgroups in a language family
- identify areal connections by searching for likely borrowings
- check for similar and diverse layers in the lexicon
Benefits
Prepare Data
If data can be processed by a computer, it can also be checked. Once your data is machine-readable, you can do a lot of interesting things beyond searching for cognates, such as:
- deriving automatic phonotactic information
- deriving information on phoneme inventories
- deriving information on colexifications and language-internal lexical associations
Benefits
Increase Transparence
If automatic cognates can be computed, you can also compute automatic alignments, and alignments have a huge advantage over a simple listing of cognate sets, since they make even the human judgment much more transparent.
Benefits
Increase Transparence

Benefits
Increase Transparence
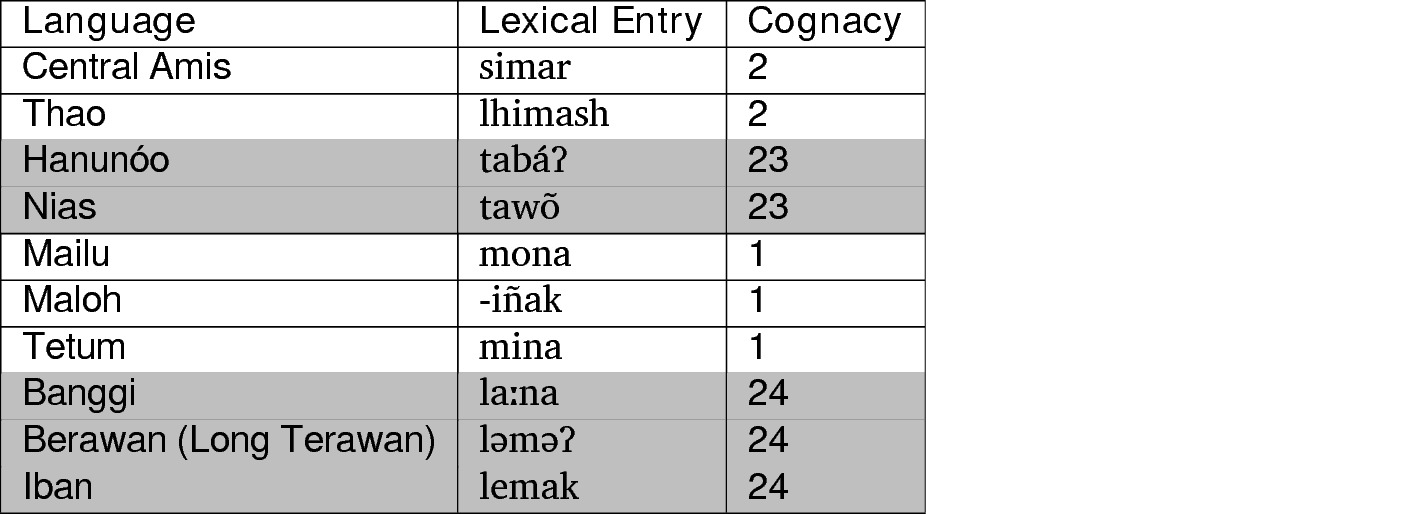
Benefits
Increase Transparence

Benefits
Summary
If we want to bring historical linguistics into the quantitative and empirical era, we need to increase the transparency of our judgments and analyses. By producing data which is not only human- but also computer-readable, we cannot only use it to carry out automatic tests, but we will generally help to put the comparative methods on more solid grounds.
Data

Data
Formats
Specific formats are needed to analyse linguistic data with LingPy and search automatically for cognates. The basic format used in LingPy is a tab-separated input file in which the first row serves as a header and defines the content of the rest of the rows. The very first column is reserved for numerical identifiers, while the order of the other columns is arbirtrary. To a large degree, this input format is compatible with the one advocated by the CLDF initiative.
Data
Excursus: CLDF Initiative
The Cross-Linguistic Data Formats initiative (Forkel et al. 2016, http://cldf.clld.org) aims at increasing the comparability of cross-linguistic. It comes along with:
- standardization efforts (linguistic databases like Glottolog and Concepticon),
- software APIs which help to test whether data conforms to the standards, and
- working examples for best practice
Data
LingPy Wordlist Format: Basics
ID CONCEPT COUNTERPART IPA DOCULECT COGID
1 hand Hand hant German 1
2 hand hand hænd English 1
3 hand рука ruka Russian 2
... ... ... ... ... ...
@note:Careful, this data could have been charmed!
ID CONCEPT COUNTERPART TOKENS DOCULECT COGID
# this is a field used for comments
1 hand Hand h a n t German 1
2 hand hand h æ n d English 1
3 hand рука r u k a Russian 2
... ... ... ... ... ...
Data
LingPy Wordlist Format: Basics
- "TOKENS" stores the segmented form of a phonetic transcription, if not given, LingPy will try to derive it from the column "IPA"
- ID must be numeric, but order is not important
- all letters are converted to lower case internally (UPPERCASE in output only for visibility
- each word gets its own row (!)
- use "CONCEPT" for "gloss, meaning", etc.
- use "DOCULECT" for "language" etc.
- "COGID" is a numeric identifier for cognate sets which denotes cognate sets across concepts (reserved for expert cognate judgments)
Data
LingPy Wordlist Format: Specifics
- missing data is not displayed (LingPy automatically calculates empty spots, they don't matter for cognate detection)
- synonyms (two or more words for the same meaning in the same language) are given separate IDs and put into different rows
- arbitrary additional columns can be added, as long as the header does not contain spaces and is written in alphanumeric form (first letter must be an alphabetic letter)
Data
LingPy Wordlist Format: Segments and Alignments
- alignments are just another column ("ALIGNMENT")
- they are defined for a cognate sets ("COGID")
- they require that the words are segmented ("TOKENS")
ID CONCEPT DOCULECT COGID TOKENS ALIGNMENT
1 Harry German 1 h a r a l t h a r a l t
2 Harry English 1 h æ r i h æ r i - -
3 Harry Russian 1 g a r i g a r i - -
... ... ... ... ... ...
Data
LingPy Wordlist Representation
LingPy offers a generic Wordlist class to represent and manipulate word lists. From the Python terminal (e.g., Ipython), you can easily read a wordlist and then either query or modify its content:
>>> from lingpy import *
>>> wl = Wordlist('polynesian.tsv')
>>> print("Concepts:", wl.height, "Languages:", wl.width)
Concepts: 210 Languages: 37
Data
LingPy Wordlist Representation
Wordlists allow you to slice data in different ways. In general, internally, they represent data from the perspective of the "row" (the concept) and the "column" (the language). To query which words (represented by the indices) occur in the concept for "hand/arm", you can thus write:
>>> wl.get_list(row="HAND", flat=True)
[2050, ...]
>>> wl.get_list(col="Anuta", flat=True)
[2179, ...]
More information can be found at http://lingpy.org/tutorial/lingpy.basic.wordlist.html.
Data
LingPy Wordlist Representation
The most crucial aspect is that you can retrieve every word in the data with help of its integer key. Using only the key, you will get the full row of a wordlist object, but if you add the column name, you will get the value in the respective cell:
>>> wl[2050]
['abvd-abvd-253-1', 'anut1237', '1277', 'Anuta', 'HAND', 'rima',
['r', 'i', 'm', 'a']
>>> wl[2050, 'tokens']
['r', 'i', 'm', 'a']
Data
LingPy Segmentation Checking
LingPy can automatically segment the phonetic data provided by the user. If LingPy compares sequences, these are in general converted to an internal format which breaks down their complexity to that of a smaller alphabet of sound classes.
>>> ipa2tokens('tʰɔxtɐ')
['tʰ', 'ɔ', 'x', 't', 'ɐ']
>>> tokens2class(['tʰ', 'ɔ', 'x', 't', 'ɐ'], 'sca')
['T', 'U', 'G', 'T', 'E']
If LingPy does not correctly recognize a symbol (e. g., because it is erroneous), it represents it internally as a "0". We can use this to check the quality of the input data.
>>> tokens2class(['tʰ', '?', 'x', 't', 'ɐ'], 'sca')
['T', '0', 'G', 'T', 'E']
Data
LingPy Segmentation Checking
It is crucial to check that all data has been converted properly and that LingPy "knows" all symbols. Otherwise, many strange things can happen in the analysis, and the results will be disappointing.
Data
LingPy Coverage Checking
Coverage (how many data points are there per word and language in a given dataset) is crucial for the success of the more advanced analyses provided by LingPy (LexStat, LexStat with Infomap clustering). If coverage goes beyond a certain level (rule of thumb: less than 100 word pairs in two languages), no sound-correspondence signal can be found, and LingPy won't find cognates even in words which look obviously similar.
Methods
Methods
Overview
Two major aspects of sequence comparison include:
- alignment analyses (SCA algorithm for multiple phonetic alignments, List 2012a)
- automatic cognate detection (LexStat algorithm, List 2012b)
Methods
Overview
Both can be carried out automatically in LingPy and visualized and inspected with help of the EDICTOR tool. Both analyses are based on rather complicated workflows which require a good knowledge of the relevant papers to understand all parameters that can be used when applying the algorithms. All algorithms are described in detail in List (2014). It is recommended to be careful when modifying the parameters and to inform the LingPy core developer team (http://github.com/lingpy/lingpy) in case of strange results.
Methods
Workflow: SCA Alignments

Methods
Workflow: LexStat
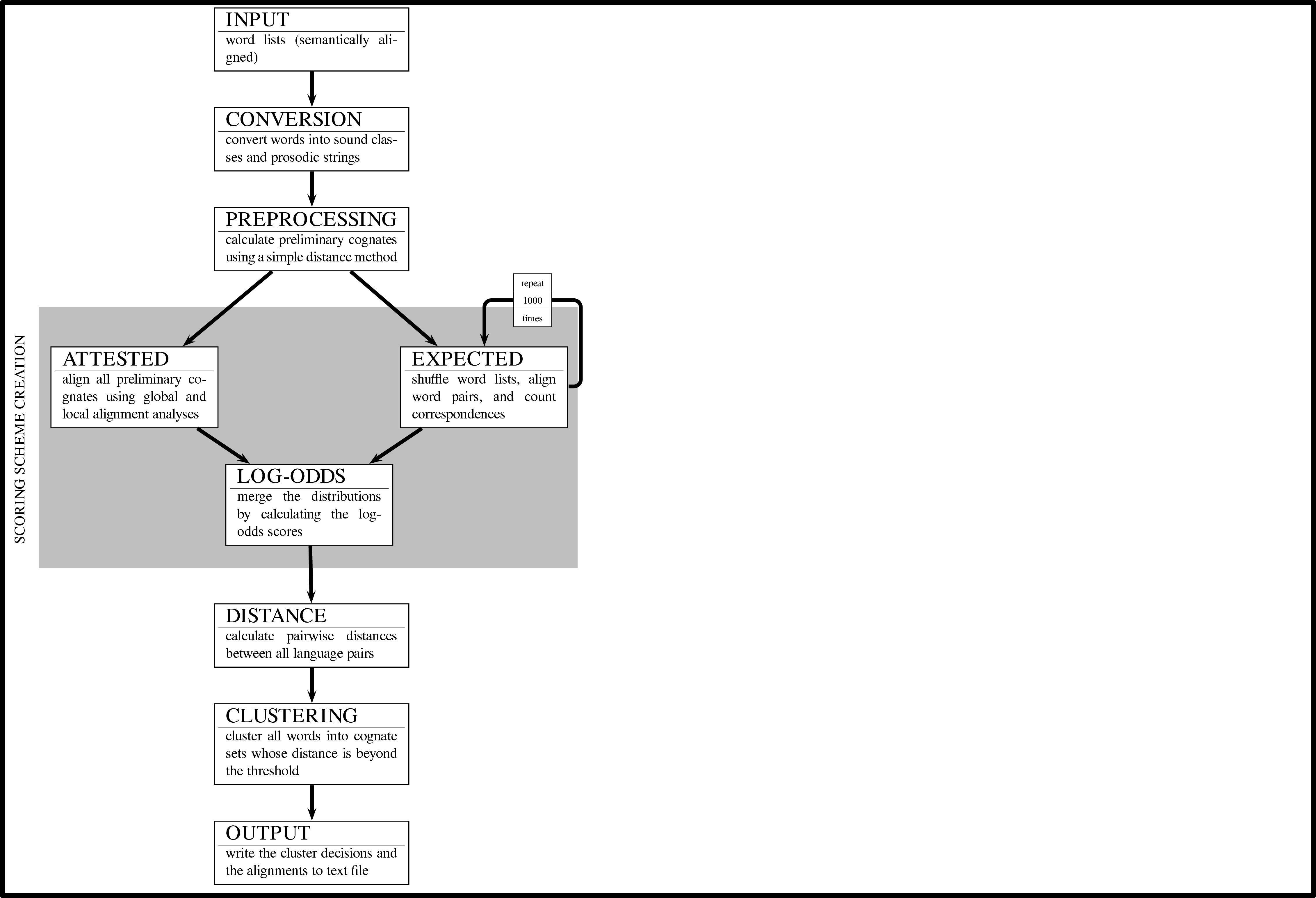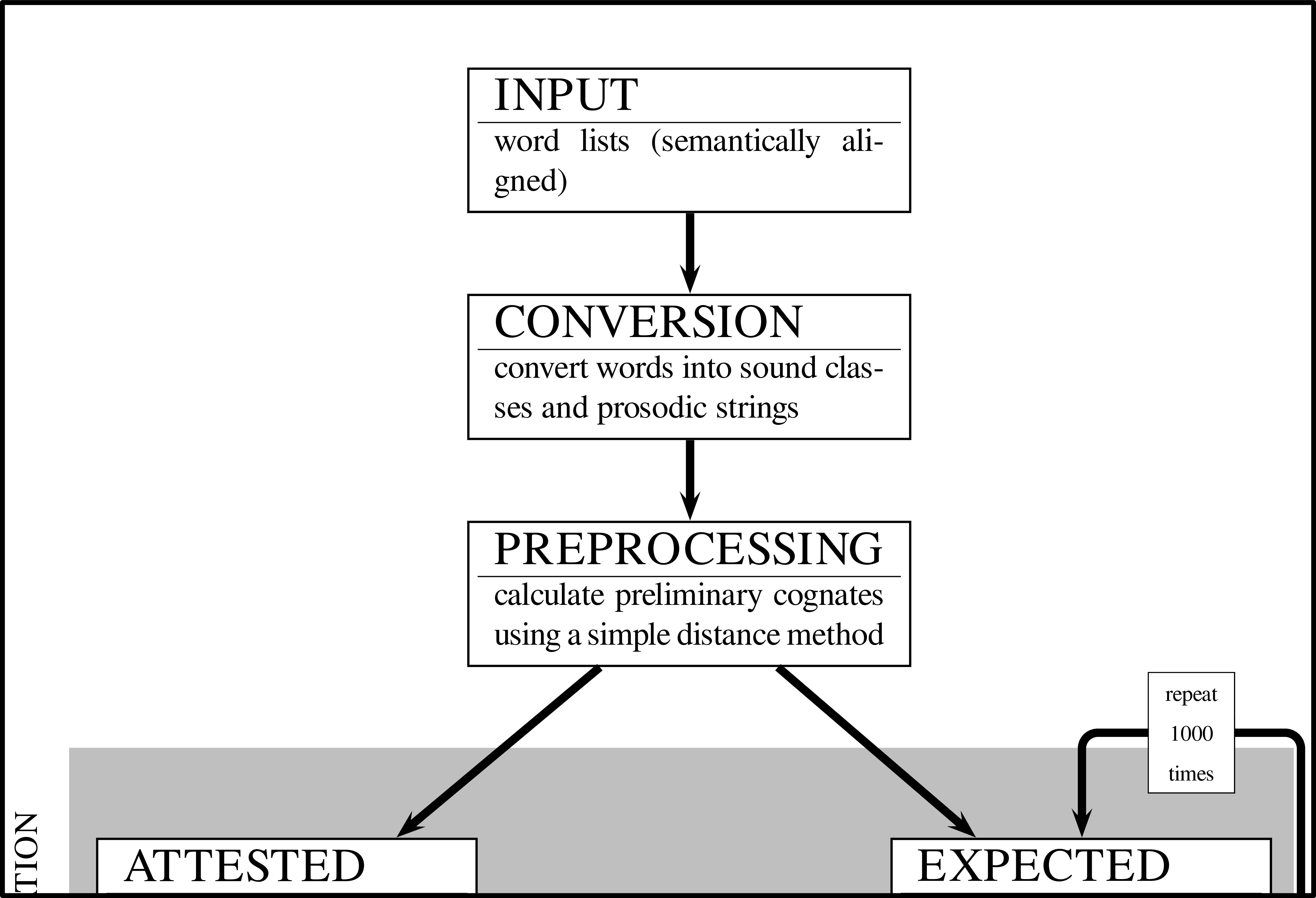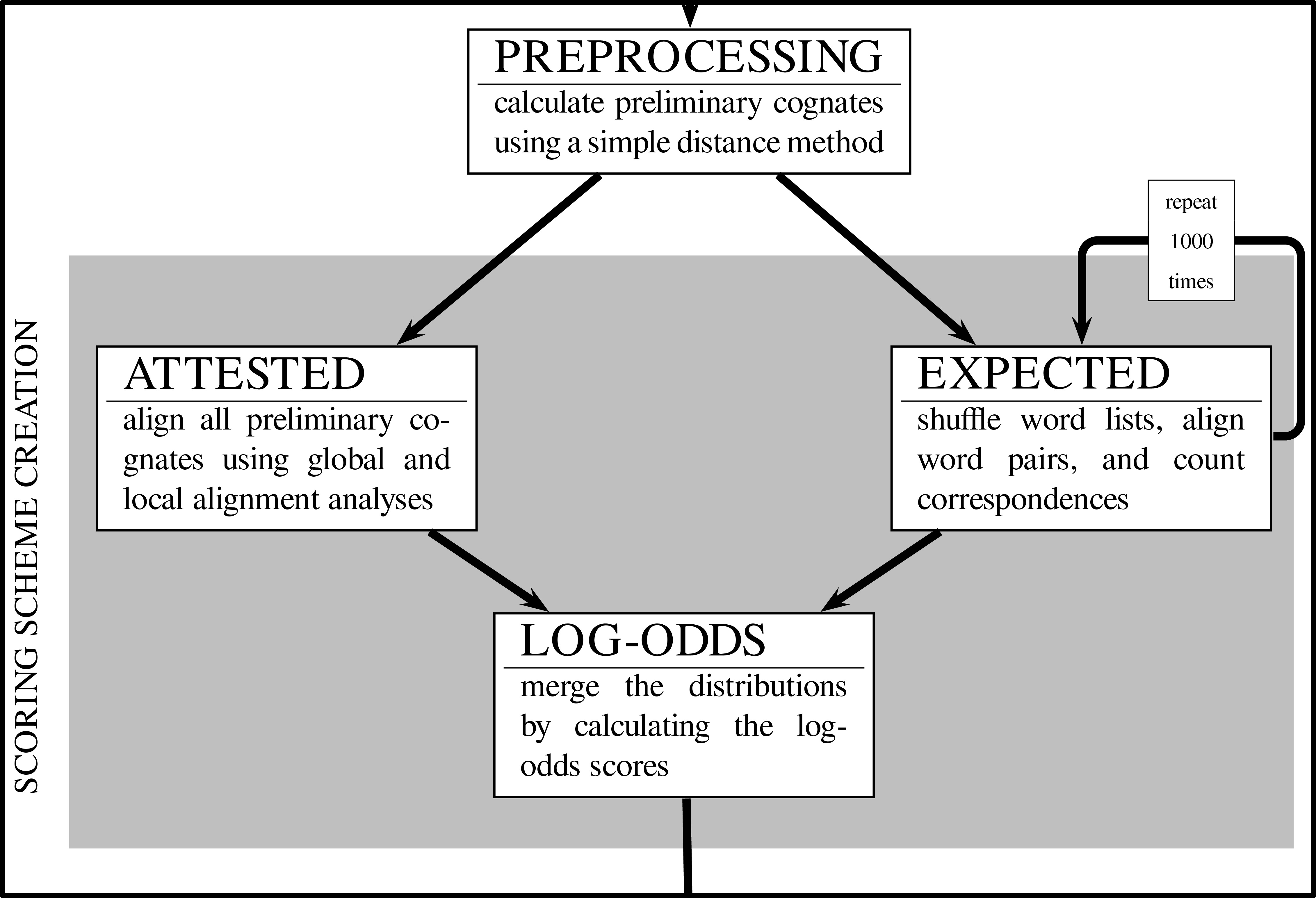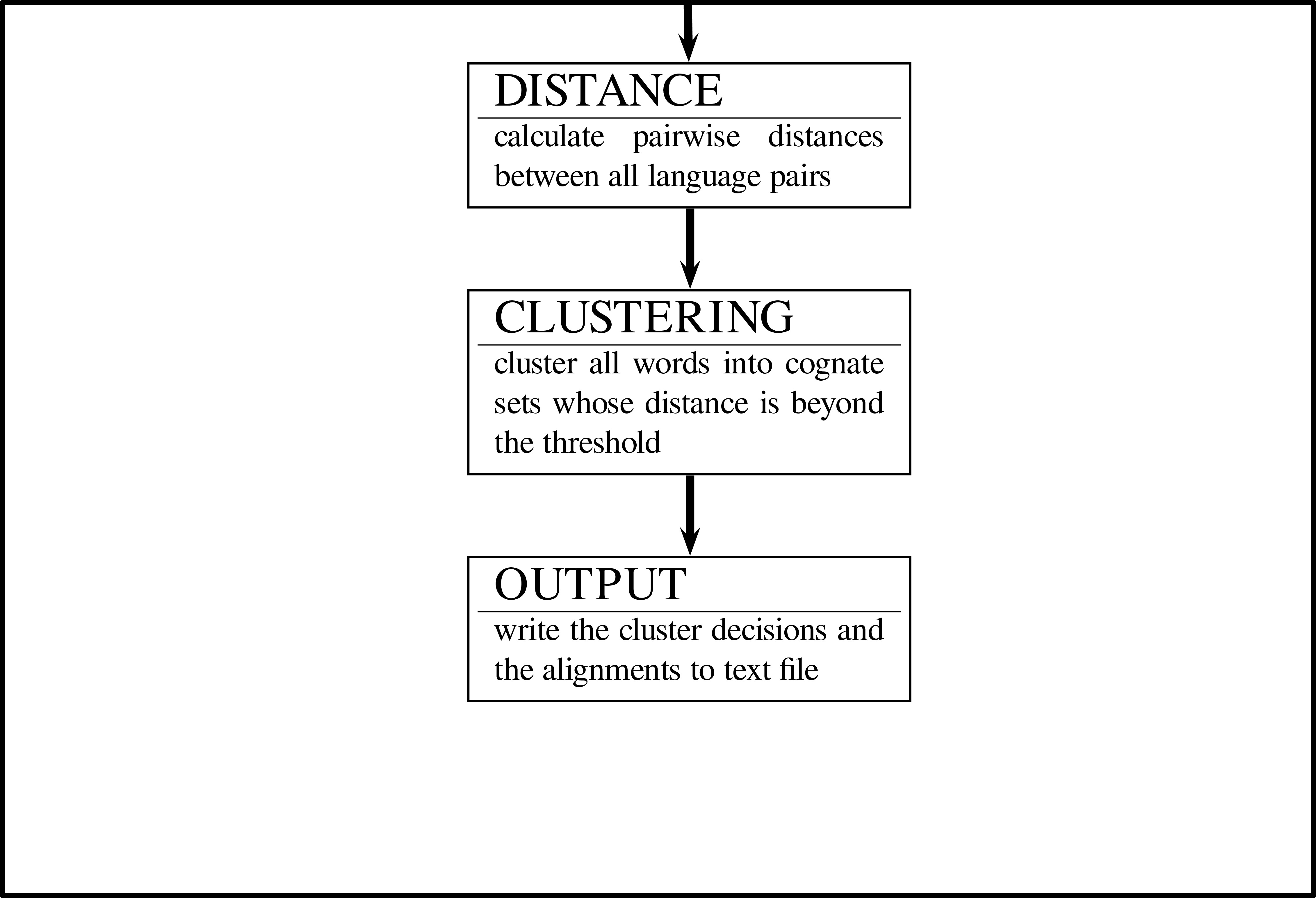
Methods
Workflow: LexStat
There are three major phases in LexStat:
- calculating a language-specific scoring function (aka pairwise sound correspondences for all language pairs)
- calculating distances for all sequences in the same concept slot (distance calculation)
- clustering the sequences into sets of probably cognate words using a flat clustering algorithm and the information on pairwise sequence distances (partition phase)
Methods
Workflow: LexStat
- Method "dolgopolsky" (after Dolgopolsky 1964): neither of the three steps required, sounds are only converted to very rough sound classes
- Methods "edit-dist" and "sca": steps 2 and 3 are required and carried out in one run, a threshold needs to be defined which determines when sequences are clustered into cognate sets and when not.
- Method "lexstat": all steps are required, threshold determines how to cluster sequences into cognate sets.
Analysis
![]()
Analysis
Practice
The tutorial is available on GitHub at https://github.com/shh-dlce/qmss-2017 (folder LingPy).
Analysis
Interpretation
We inspect the results with help of the EDICTOR tool at http://edictor.digling.org (List 2017).
Analysis
Further Use
By exporting the data to NEXUS, or to Phylip Distance format, we can further load the results of the analysis into software packages like SplitsTree or BEAST, which allow for more fine-grained and detailed phylogenetic analyses.
Thanks for Your Attention!