CLTS
Establishing a Cross-Linguistic Database of Phonetic Notation Systems
![]()
Agenda 2017
- Comparability of Cross-Linguistic Data
- Phonetic Transcription Systems
- Cross-Linguistic Data Formats
- Cross-Linguistic Transcription Systems
Comparability of Linguistic Data

Comparability of Linguistic Data
Background
- linguistics is a data-driven discipline
- every linguist out there profits or has profited from colleagues sharing their data
- we still mess it up oftentimes
Comparability of Linguistic Data
Examples
- grammatical description and comparison
- phonetic description and historical comparison
- lexical description and lexical comparison
Comparability of Linguistic Data
Problems
- availability
- transparency
- comparability
Comparability of Linguistic Data
Problems: Availability

Be careful, this presentation may contain fake news!
Comparability of Linguistic Data
Problems: Transparency
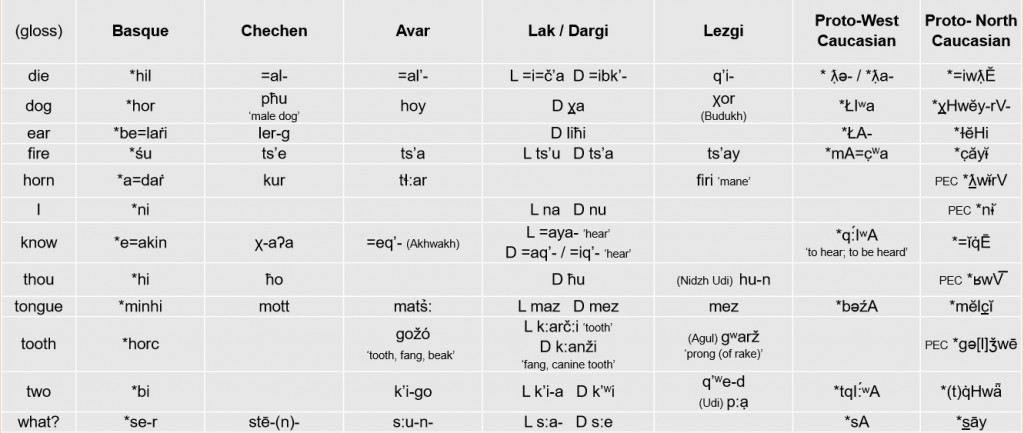
Taken from a blog by Bengtson (2017) at http://euskararenjatorria.net/?p=26071
Comparability of Linguistic Data
Problems: Comparability
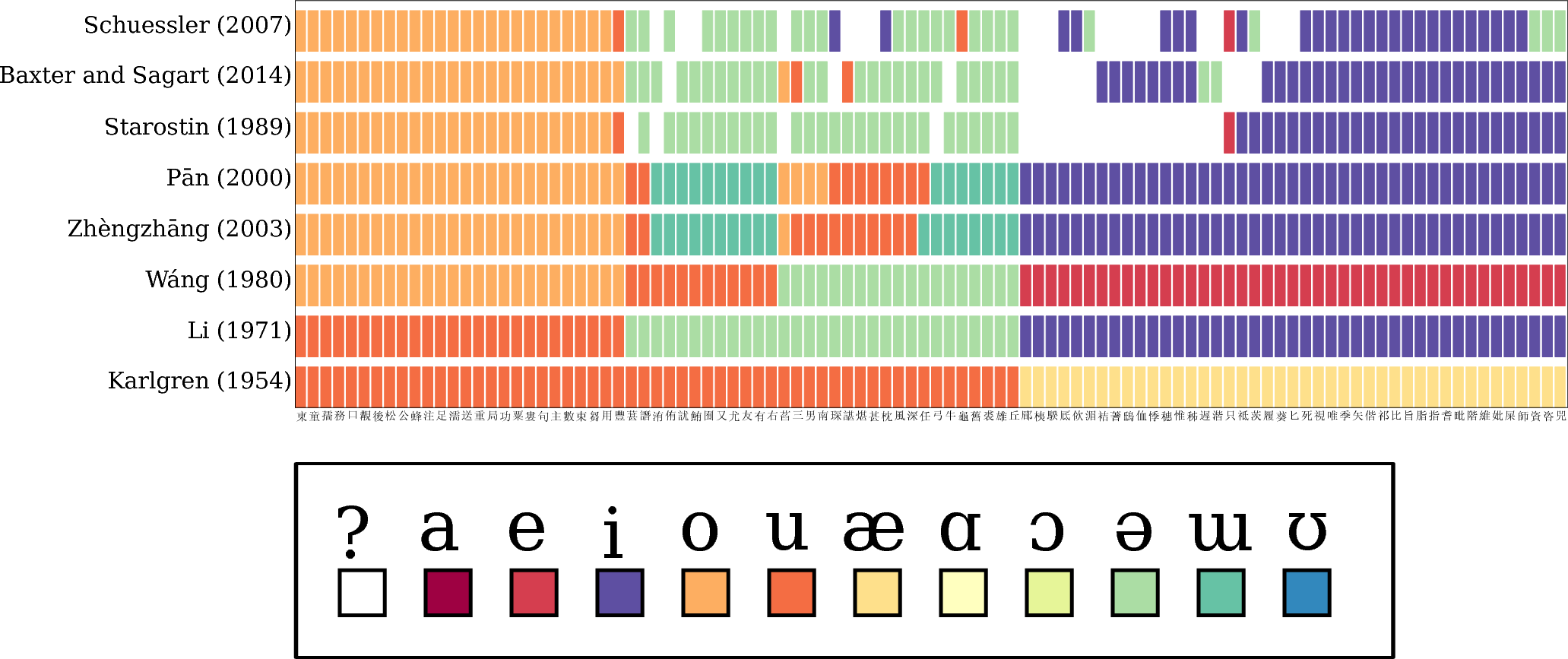
Comparing different reconstruction systems for Old Chinese (List et al. 2017)
Phonetic Transcription Systems
![]()
Phonetic Transcription Systems
Background
- North American Phonetic Alphabet
- International Phonetic Alphabet
- Uralic Phonetic Alphabet
- Teutonista
- Sinologists, Africanologists, Americanologists, ...
Phonetic Transcription Systems
IPA
- "IPA inside" may mean different things
- "IPA" itself creates ambiguities
- "IPA" is not a standard, as it does not provide evaluation tools, but instead a set of suggestions
- "IPA" suggestions are disregarded and ignored by linguists in multiple ways
- see Moran and Cysouw (2017) for details on Unicode and IPA pitfalls...
Phonetic Transcription Systems
Comparative Databases
- Ruhlen's (2008) Global linguistic database (written in NAPA with modifications)
- Starostin's Global Lexicostatistical Database (unified transcription system, which deviates from IPA)
- Mielke's (2008) PBase, a database of phonological patterns, uses IPA (with some modifications and inconsistencies)
- Phoible (Moran et al. 2015), a database of phoneme inventories, uses IPA (with some modifications and inconsistencies)
- The IPA regularly publishes (now also digitally) its Illustrations of the IPA which should be the standard, but are not formally tested
Phonetic Transcription Systems
Comparative Databases
- Wikipedia has a large collection of Language phonologies in which the IPA is supposed used, but which are not formally tested
- field workers all of the world produce data in transcriptions that are supposed to conform to the IPA, but they often largely differ regarding their respective strictness of adhering to IPA
- the ASJP project designed a short alphabet to gather rough transcriptions of lexical items of different languages of the world
- Fonetikode (Dediu and Moisik 2016) is an attempt to link Ruhlen's and Phoible's sounds to a new feature system, but they do not use the original Ruhlen data and do not provide annotations for all symbols
Phonetic Transcription Systems
Comparative Databases
| Dataset | Transcr. Syst. | Sounds |
|---|---|---|
| GLD (Ruhlen 2008) | NAPA (modified) | 600+ (?) |
| Phoible (Moran et al. 2015) | IPA (specified) | 2000+ |
| GLD (Starostin 2015) | UTS | ? |
| ASJP (Wichmann et al. 2016) | ASJP Code | 700+ |
| PBase (Mielke 2008) | IPA (specified) | 1000+ |
| Wikipedia | IPA (unspecified) | ? |
| JIPA | IPA (norm?) | 800+ |
Cross-Linguistic Data Formats

Cross-Linguistic Data Formats
Background
The Cross-Linguistic Data Formats initiative (Forkel et al. 2016, http://cldf.clld.org) comes along with:
- standardization efforts (linguistic meta-data-bases like Glottolog, Concepticon, and CLTS)
- software APIs which help to test and use the data
- working examples for best practice
Cross-Linguistic Data Formats
Technical Aspects
- See http://github.com/glottobank/cldf for details, discussions, and working examples.
- Format for machine-readable specification is CSV with metadata in JSON, following the W3C’s Model for Tabular Data and Metadata on the Web (http://www.w3.org/TR/tabular-data-model/).
- CLDF ontology builds and expands upon the General Ontology for Linguistic Description (GOLD).
- pcldf API in Python is close to first release and can be used to test datasets whether they conform to CLDF
Cross-Linguistic Data Formats
Standards
- Wordlist standard (integrated into various tools like LingPy, Beastling, and EDICTOR)
- Dictionary standard (will be the basic for the Dictionaria project, http://dictionaria.clld.org)
- Feature standard (basic ways to handle grammatical features in cross-linguistic datasets)
Cross-Linguistic Data Formats
Meta-Data-Bases
- Concepticon (List et al. 2016) handles concepts across different datasets and questionnaires.
- Glottolog (Hammarström et al. 2017) helps to handle languages via unique identifiers.
- CLTS (this talk) is supposed to provide the missing standard for the handling of phonetic transcription systems by providing unique identifiers across distinct sounds which can be found across linguistic datasets
Cross-Linguistic Transcriptions
![]()
Cross-Linguistic Transcriptions
Objectives
- provide a standard for phonetic transcription for the purpose of cross-linguistic studies
- standardized ways to represent sound values serve as "comparative concepts" in the sense of Haspelmath (2010)
- similar to the Concepticon, we want to allow to register different transcription systems but link them with each other by linking each transcription system to unique sound segments
Cross-Linguistic Transcriptions
Objectives
- in contrast to Phoible or other databases which list solely the inventories of languages, CLTS is supposed to serve as a standard for the handling of lexical data in the CLDF framework, as a result, not only sound segments need to be included in the framework, but also ways to transcribe lexical data consistently
Cross-Linguistic Transcriptions
Strategy
- register transcription systems by linking the sounds to phonetic feature bundles which serve as identifier for sound segments
- apply a three-step normalization procedure that goes from (1) NFD-normalization (Unicode decomposed characters), (2) via Unicode confusables normalization, to (3) dedicated Alias symbols
- divide sounds in different sound classes (vowel, consonant, diphthong, cluster, click, tone) to define specific rules for their respective feature sets
Cross-Linguistic Transcriptions
Strategy
- allow for a quick expansion of the set of features and the sound segments for each alphabet by applying a procedure that tries to guess unknown sounds by decomposing them into base sounds and diacritics
- use the feature bundles and the different transcription systems to link the transcription systems with various datasets, like Phoible, LingPy's sound class system, Wikipedia's sound descriptions, or the binary feature systems published along with PBase
- features are not ambitious in the sense of being minimal, ordered, exclusive, binary, etc., but serve as a means of description, following the IPA as closely as possible
Cross-Linguistic Transcriptions
Examples: Three-Step-Normalization
| In | NFD | Confus. | Alias | Out |
|---|---|---|---|---|
| ã (U+00E3) | a (U+0061) ◌̃ (U+0303) | ã | ||
| a (U+0061) : (U+003a) | a (U+0061) ː (U+02d0) | aː | ||
| ʦ (U+02a6) | t (U+0074) s (U+0073) | ts |
Cross-Linguistic Transcriptions
Examples: Three-Step-Normalization
| In | Identifier |
|---|---|
| ã | nasalized unrounded open front vowel |
| aː | long unrounded open front |
| ts | voiceless alveolar affricate consonant |
Cross-Linguistic Transcriptions
Statistics: Now
- two transcription systems: ASJP and B(road)IPA
- three metadata sets: Phoible, LingPy, Wikipedia
- Python API works on Python3
- Web-Application allows to check whether data conforms to BIPA or not
Cross-Linguistic Transcriptions
Statistics: Now
| Dataset | Matched | Generated | Missed | Perc. |
|---|---|---|---|---|
| Phoible | 613 | 616 | 772 | 61% |
| JIPA (142 lang.) | 515 | 2 | 377 | 58% |
| PBase | 496 | 265 | 521 | 59% |
Cross-Linguistic Transcriptions
Statistics: Planned
- four more transcription systems (UPA, NAPA, GLD-UTS, X-SAMPA)
- more metadata (Index Diachronica, Ruhlen's Database, sound examples)
- full platform and all-version Python API
- enhanced web-application (select between transcription systems, translate, etc.)
Outlook

Outlook
Why?
- corpus-based sound inventories
- increase comparability of lexical data
- obtain new insights into sound change
- evaluate consistency of linguistic data



Thanks for Your Attention!
