Computer-Assisted Language Comparison
Reconciling Classical and Computational Approaches in Historical Linguistics
![]()
Agenda 2017
- Introduction
- Data
- Software
- Tools
- Outlook
Introduction

Introduction
Classical Historical Linguistics
- Traditional methods of historical linguistics are based on manual data annotation.
- With more data available, they reach their practical limits.
Introduction
Computational Historical Linguistics
- Computational methods are fast and efficient, but not very accurate.
- Computational methods cannot replace experience and intution of experts.
Introduction
Computer-Assisted Language Comparison
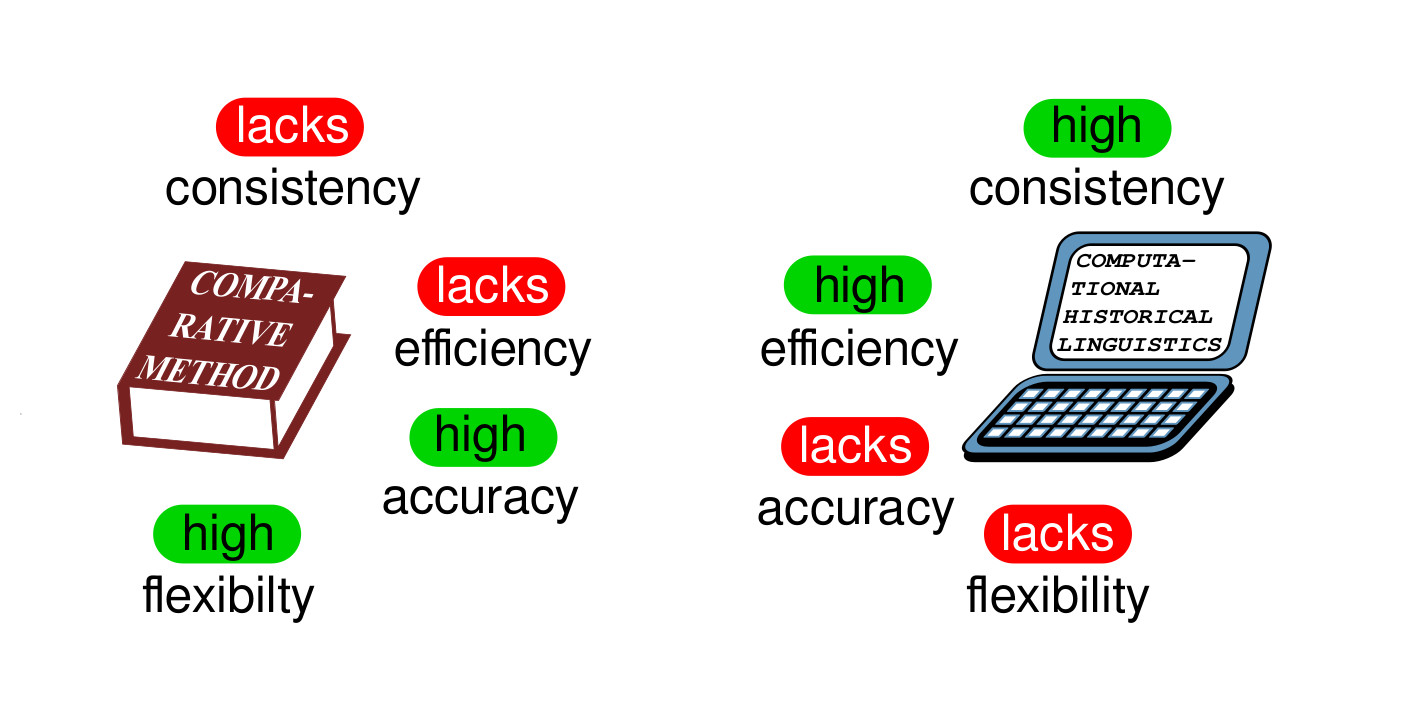
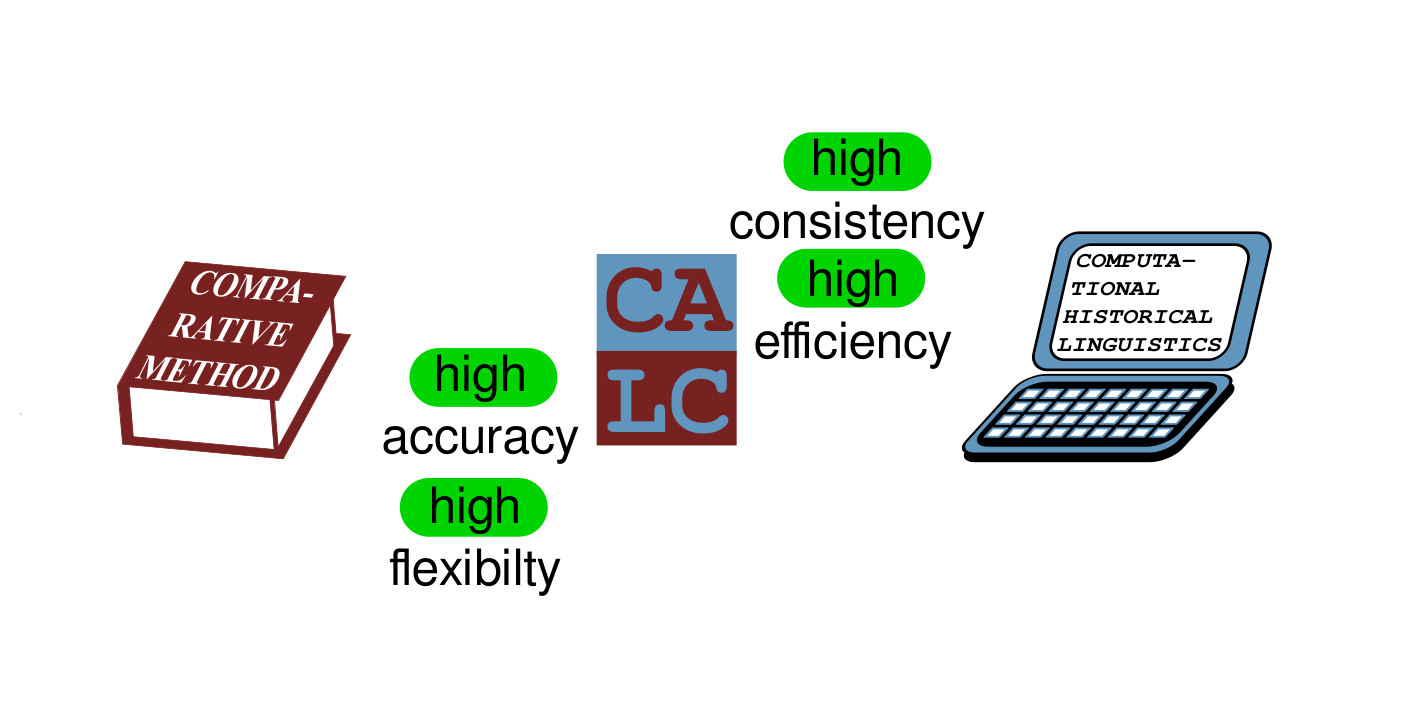
- Since experts are slow, while computers are not very accurate, we need combined frameworks that reconcile classical and computational approaches.
- Computer-assisted language comparison may drastically increase the consistency of expert annotation while correcting for the lack of accuracy in computational analyses.

Data

Data
Introduction
- Data needs to be accessible in human- and machine-readable form.
- Data needs to be normalized, as far as this is possible.
- All information should be presented and stored explicitly, implicit storage of information should be avoided.
Data
Cross-Linguistic Data Formats
The Cross-Linguistic Data Formats initiative (Forkel et al. 2016, http://cldf.clld.org) aims at increasing the comparability of cross-linguistic. It comes along with:
- standardization efforts (linguistic databases like Glottolog and Concepticon),
- software APIs which help to test whether data conforms to the standards, and
- working examples for best practice
Data
Cross-Linguistic Data Formats
As of now, a couple of software tools (LingPy, Beastling, EDICTOR) support CLDF. In the future, we hope that the number of users will increase, and that the community helps to develop the formats further.
Data
Examples
- Concepts in wordlist data should be linked to the Concepticon resource (List et al. 2016).
- Language data should be linked to Glottolog (Hammarström et al. 2015).
- Phonetic data should be standardized to a global phonetic alphabet (current efforts are done in the Cross-Linguistic Phonetic Alphabet project).
Data
Exampes: Concepticon
The Concepticon is an attempt to link the large amount of different concept lists which are used in the linguistic literature, ranging from Swadesh lists in historical linguistics to naming tests in clinical studies and psycholinguistics.
Data
Exampes: Concepticon
This resource, our Concepticon, links concept labels from different conceptlists to concept sets. Each concept set is given a unique identifier, a unique label, and a human-readable definition. Concept sets are further structured by defining different relations between the concepts.
http://concepticon.clld.org
Data
Exampes: Concepticon
With the verson 1.1 of Concepticon, which will be released later in 2017, many new features become available:
- increased data (about 200 different concept lists)
- improved automatic linking of new concept lists (multi-lingual, data-driven, efficient)
- improved methods for concept list comparison
Data
Cross-Linguistic Transcription Systems
This is an attempt to create a cross-linguistic phonetic alphabet, realized as a dialect of IPA, for cross-linguistic approaches to language comparison.
The basic idea is to provide a fixed set of symbols for phonetic representation along with a full description regarding their pronunciation following the tradition of IPA. This list is essentially expandable, when new language data arises, and can be linked to alternative datasets, like Mielke's (2008) P-Base, and PHOIBLE.
Data
Cross-Linguistic Transcription Systems
Efforts are extremely preliminary and also experimental. A rather new idea is to use orthography profiles (Moran and Cysouw 2017) to automatically convert between consistent alphabets (like, e.g., the GLD alphabet) and CLPA, or to adjust existing datasets so that they conform to CLPA standards.
GLD to CLPA
Data
Cross-Linguistic Transcription Systems
| ID | Language_ID | Parameter_ID | Value | Segments |
|---|---|---|---|---|
| 1 | stan1295 | 1277 | Hand (n) | h a n t |
| 2 | stan1293 | 1277 | hand | h æ n d |
| 3 | russ1263 | 2121 | рука | r u ˈk a |
| ... | ... | ... | ... | ... |
Software

Software
Introduction
- Software is needed to preprocess the data, so that it can later be quickly corrected by a human expert.
- For many purposes, current algorithms are good enough to provide real help in data-preprocessing.
Software
Algorithms
- Cognate Detection
- Ancestral State Reconstruction
- Colexification Pattern Analysis
Software
LingPy
- Python library for quantitative tasks in historical linguistics
- offers many methods for sequence comparison (phonetic alignment, cognate detection), phylogenetic reconstruction, ancestral state reconstruction, etc.
- can read CLDF files
Software
LingPy
Partial Cognate Detection (List et al. 2016)

Partial Colexification Analysis

Ancestral State Reconstruction

LINGPY.ORG
Tools
Tools
Introduction
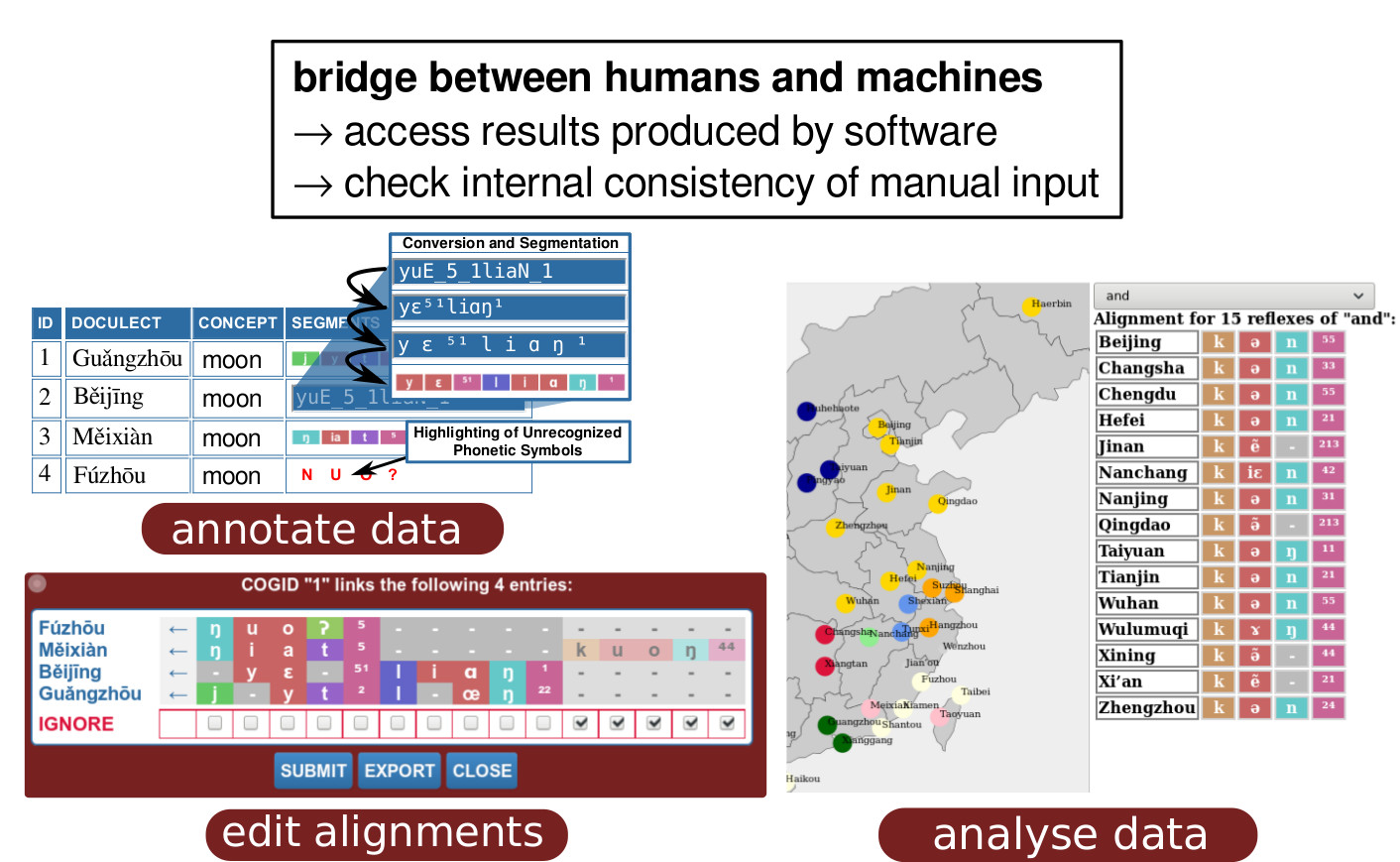
Tools or interfaces serve two major purposes in the CALC framework:
- They allow experts to inspect the results of computational analyses conveniently.
- They check the manual corrections of experts upon input.
Tools do not necessarily need to offer solutions for both of these aspects, and we will often have tools which serve only for inspection, or tools which only server for data-creation and correction.
Tools
Functionalities
Tools for data input should have the following functionalities:
- accept standardized formats as defined in the CLDF framework
- allow for an efficient data input (e.g., writing phonetic data by converting from SAMPA, etc.)
- minimize errors by checking the data upon data input
Tools
Functionalities
Tools for data inspection are less bound to standards, also since the problems they may address are so different. Nevertheless, they should also accept standardized formats as input data. In addition, we recommend to use web-based frameworks (JavaScript / CSS/ HTML) to guarantee platform independence. This will also minimize learning time for users, given that we are all nowadays quite familiar with web-based frameworks, rather than with complicated GUIs.
Tools
Examples
- EDICTOR: Etymological Dictionary Editor (List 2017)
- CLICS: Database of Cross-Linguistic Colexifications (List et al. 2013 and 2014)
Tools
EDICTOR
The EDICTOR is a web-based tool that allows to edit, analyse, and publish etymological data. It is available as a prototype in Version 0.1 and will be further developed in the project "Computer-Assisted Language Comparison" (2017-2021). The tool can be accessed via the website at http://edictor.digling.org, or be downloaded and used in offline form. All that is needed to use the tool is a webbrowser (Firefox, Safari, Chrome). Offline usage is currently restricted to Firefox. The tool is file-based: input is not a database structure, but a plain tab-separated text file (as a single sheet from a spreadsheet editor). The data-formats are identical with those used by LingPy, thus allowing for a close interaction between automatic analysis and manual refinement.
Tools
EDICTOR: Structure
The EDICTOR structure is modular, consisting of different panels that allow for:
- data editing (data input, alignments, cognate identification)
- data analysis (phonological analysis, correspondence analysis)
- customisation
EDICTOR.DIGLING.ORG
Tools
CLICS
CLICS is an online database of synchronic lexical associations ("colexifications") in currently 221 language varieties of the world. Large databases offering lexical information on the world's languages are already readily available for research in different online sources. However, the information on tendencies of meaning associations they enshrine is not easily extractable from these sources themselves.
Tools
CLICS
As CLICS comes along with a powerful visualization suite, it is very convenient to query the information regarding meaning associations. CLICS thus also serves as an example for computer-assisted language comparison, in so far as it illustrates how analyses created by machines can be made accessible to the detailed inspection by researchers.
CLICS.LINGPY.ORG
Outlook

Outlook
We are only at the beginning, and many things still need to be done:
- enhancing collaboration between scholars across different projects
- enhancing exchange between data bases (e.g., working with GLD data in LingPy, or other tools)
- propagating and enhancing CLDF as an interface format communicating between linguistic data collections



Спасибо за Ваше внимание!
![]()